International Al Safety Report: First Key Update Capabilities and Risk Implications
DOI:
https://doi.org/10.70777/si.v2i6.16253Keywords:
AI capabilities, General-purpose AI systems, Reasoning models, autonomous ai, Biological risks, Cyber security, AI companions, ai Labour market impact, AI oversight, ai governance, AI safeguardsAbstract
The field of AI is moving too quickly for a single yearly publication to keep pace. Significant changes can occur on a timescale of months, sometimes weeks. This is why we are releasing Key Updates: shorter, focused reports that highlight the most important developments between full editions of the International AI Safety Report. With these updates, we aim to provide policymakers, researchers, and the public with up-to-date information to support wise decisions about AI governance.
This first Key Update focuses on areas where especially significant changes have occurred since January 2025: advances in general-purpose AI systems' capabilities, and the implications for several critical risks. New training techniques have enabled AI systems to reason step-by-step and operate autonomously for longer periods, allowing them to tackle more kinds of work. However, these same advances create new challenges across biological risks, cyber security, and oversight of AI systems themselves.
The International AI Safety Report is intended to help readers assess, anticipate, and manage risks from general-purpose AI systems. These Key Updates ensure that critical developments receive timely attention as the field rapidly evolves.
References
M. Skarlinski, J. Laurent, A. Bou, A. White, “About 30% of Humanity’s Last Exam Chemistry/ Biology Answers Are Likely Wrong” (FutureHouse, 2025); https://futurehouse.org/research/hlebio- chem-analysis
H. Wallach, M. Desai, A. Feder Cooper, A. Wang, C. Atalla, S. Barocas, S. L. Blodgett, A. Chouldechova, E. Corvi, P. Alex Dow, J. Garcia-Gathright, A. Olteanu, N. J. Pangakis, S. Reed, E. Sheng, D. Vann, J. W. Vaughan, … A. Z. Jacobs, “Position: Evaluating Generative AI Systems Is a Social Science Measurement Challenge” in 42nd International Conference on Machine Learning Position Paper Track (2025); https://openreview.net/forum?id=1ZC4RNjqzU
O. Salaudeen, A. Reuel, A. Ahmed, S. Bedi, Z. Robertson, S. Sundar, B. Domingue, A. Wang, S. Koyejo, Measurement to Meaning: A Validity- Centered Framework for AI Evaluation, arXiv [cs.CY] (2025); http://arxiv.org/abs/2505.10573
K.-H. Huang, A. Prabhakar, S. Dhawan, Y. Mao, H. Wang, S. Savarese, C. Xiong, P. Laban, C.-S. Wu, “CRMArena: Understanding the Capacity of LLM Agents to Perform Professional CRM Tasks in Realistic Environments” in Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (Association for Computational Linguistics, Stroudsburg, PA, USA, 2025), pp 830–3850; https://doi.org/10.18653/ v1/2025.naacl-long.194
S. Ye, H. Shi, D. Shih, H. Yun, T. Roosta, T. Shu, RealWebAssist: A Benchmark for Long-Horizon Web Assistance with Real-World Users, arXiv [cs. AI] (2025); http://arxiv.org/abs/2504.10445
S. Wu, M. Galley, B. Peng, H. Cheng, G. Li, Y. Dou, W. Cai, J. Zou, J. Leskovec, J. Gao, “CollabLLM: From Passive Responders to Active Collaborators” in 42nd International Conference on Machine Learning (2025); https://openreview. net/forum?id=DmH4HHVb3y
A. Challapally, C. Pease, R. Raskar, P. Chari, “The GenAI Divide: State of AI in Business 2025” (MIT NANDA, 2025); https://mlq.ai/ media/quarterly_decks/v0.1_State_of_AI_in_ Business_2025_Report.pdf
D. Castelvecchi, DeepMind and OpenAI Models Solve Maths Problems at Level of Top Students. Nature 644, 20 (2025); https://doi.org/10.1038/ d41586-025-02343-x
J. He, C. Treude, D. Lo, LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead. ACM Transactions on Software Engineering and Methodology 34, 1–30 (2025); https://doi.org/ 10.1145/3712003
C. Qian, W. Liu, H. Liu, N. Chen, Y. Dang, J. Li, C. Yang, W. Chen, Y. Su, X. Cong, J. Xu, D. Li, Z. Liu, M. Sun, “ChatDev: Communicative Agents for Software Development” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Association for Computational Linguistics, Stroudsburg, PA, USA, 2024), pp 5174–15186; https://doi.org/10.18653/ v1/2024.acl-long.810
R. Y. Pang, H. Schroeder, K. S. Smith, S. Barocas, Z. Xiao, E. Tseng, D. Bragg, “Understanding the LLM-Ification of CHI: Unpacking the Impact of LLMs at CHI through a Systematic Literature Review” in Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (ACM, New York, NY, USA, 2025), pp –20; https://doi. org/10.1145/3706598.3713726
OpenAI, “ChatGPT Agent System Card” (2025); https://cdn.openai.com/pdf/839e66fc- 602c-48bf-81d3-b21eacc3459d/chatgpt_agent_ system_card.pdf
L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, M. Choi, A. Agrawal, A. Chopra, A. Khoja, R. Kim, R. Ren, J. Hausenloy, … D. Hendrycks, Humanity’s Last Exam, arXiv [cs.LG] (2025); https://agi.safe.ai/
Scale AI, Humanity’s Last Exam (2025); https://scale.com/leaderboard
Epoch AI, Data on AI Models (2024); https://epoch.ai/data/ai-models
Kimi Team, Y. Bai, Y. Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y. Chen, Y. Chen, Y. Chen, Z. Chen, J. Cui, H. Ding, M. Dong, A. Du, C. Du, D. Du, … X. Zu, Kimi K2: Open Agentic Intelligence, arXiv [cs.LG] (2025); http://arxiv.org/ abs/2507.20534
OpenAI, S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y. Bai, B. Baker, H. Bao, B. Barak, A. Bennett, T. Bertao, N. Brett, E. Brevdo, G. Brockman, … S. Zhao, Gpt-Oss-120b & Gpt-Oss-20b Model Card, arXiv [cs.CL] (2025); http://arxiv.org/ abs/2508.10925
D. Bahdanau, P. Brakel, K. Xu, A. Goyal, R. Lowe, J. Pineau, A. Courville, Y. Bengio, “An Actor-Critic Algorithm for Sequence Prediction” in International Conference on Learning Representations (2017); https://openreview.net/ forum?id=SJDaqqveg
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, D. Amodei, “Deep Reinforcement Learning from Human Preferences” in Proceedings of the 31st International Conference on Neural Information Processing Systems (Curran Associates Inc., Red Hook, NY, USA, 2017) NIPS’17, pp 02–4310; https://dl.acm.org/ doi/10.5555/3294996.3295184
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, … R. Lowe, “Training Language Models to Follow Instructions with Human Feedback” in Proceedings of the 36th International Conference on Neural Information Processing Systems (Curran Associates Inc., Red Hook, NY, USA, 2022) NIPS ’22; https://dl.acm.org/ doi/10.5555/3600270.3602281
W. Huang, B. Jia, Z. Zhai, S. Cao, Z. Ye, F. Zhao, Z. Xu, Y. Hu, S. Lin, Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models, arXiv [cs.CV] (2025); http://arxiv.org/abs/2503.06749
F. Xu, Q. Hao, Z. Zong, J. Wang, Y. Zhang, J. Wang, X. Lan, J. Gong, T. Ouyang, F. Meng, C. Shao, Y. Yan, Q. Yang, Y. Song, S. Ren, X. Hu, Y. Li, … Y. Li, Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models, arXiv [cs.AI] (2025); http://arxiv.org/abs/2501.09686
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y. Wu, Z. F. Wu, Z. Gou, Z. Shao, … Z. Zhang, “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” (DeepSeek-AI, 2025); http://arxiv.org/ abs/2501.12948
G. Tie, Z. Zhao, D. Song, F. Wei, R. Zhou, Y. Dai, W. Yin, Z. Yang, J. Yan, Y. Su, Z. Dai, Y. Xie, Y. Cao, L. Sun, P. Zhou, L. He, H. Chen, … J. Gao, Large Language Models Post-Training: Surveying Techniques from Alignment to Reasoning, arXiv [cs.CL] (2025); http://arxiv.org/abs/2503.06072
K. Kumar, T. Ashraf, O. Thawakar, R. M. Anwer, H. Cholakkal, M. Shah, M.-H. Yang, P. H. S. Torr, F. S. Khan, S. Khan, LLM Post-Training: A Deep Dive into Reasoning Large Language Models, arXiv [cs.CL] (2025); http://arxiv.org/ abs/2502.21321
M. Besta, J. Barth, E. Schreiber, A. Kubicek, A. Catarino, R. Gerstenberger, P. Nyczyk, P. Iff, Y. Li, S. Houliston, T. Sternal, M. Copik, G. Kwaśniewski, J. Müller, Ł. Flis, H. Eberhard, Z. Chen, … T. Hoefler, Reasoning Language Models: A Blueprint, arXiv [cs.AI] (2025); http://arxiv.org/abs/2501.11223
H. Luo, N. Morgan, T. Li, D. Zhao, A. V. Ngo, P. Schroeder, L. Yang, A. Ben-Kish, J. O’Brien, J. Glass, Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning, arXiv [cs.CL] (2025); http://arxiv.org/abs/2507.16784
E. Akyürek, M. Damani, L. Qiu, H. Guo, Y. Kim, J. Andreas, The Surprising Effectiveness of Test- Time Training for Abstract Reasoning, arXiv [cs.AI] (2024); http://arxiv.org/abs/2411.07279
C. Cai, X. Zhao, H. Liu, Z. Jiang, T. Zhang, Z. Wu, J.-N. Hwang, L. Li, “The Role of Deductive and Inductive Reasoning in Large Language Models” in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Association for Computational Linguistics, Stroudsburg, PA, USA, 2025), pp 780–16790; https://doi.org/10.18653/ v1/2025.acl-long.820
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, L. Marris, S. Petulla, C. Gaffney, A. Aharoni, N. Lintz, T. C. Pais, H. Jacobsson, … N. K. Bhumihar, “Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and next Generation Agentic Capabilities” (Google DeepMind, 2025); https://storage.googleapis.com/deepmind-media/ gemini/gemini_v2_5_report.pdf
Y. Yan, J. Su, J. He, F. Fu, X. Zheng, Y. Lyu, K. Wang, S. Wang, Q. Wen, X. Hu, “A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges” in Findings of the Association for Computational Linguistics: ACL 2025 (Association for Computational Linguistics, Stroudsburg, PA, USA, 2025), pp 798–11827; https://doi.org/10.18653/v1/2025.findings-acl.614
K. Yang, G. Poesia, J. He, W. Li, K. E. Lauter, S. Chaudhuri, D. Song, “Position: Formal Mathematical Reasoning — A New Frontier in AI” in 42nd International Conference on Machine Learning Position Paper Track (2025); https://openreview.net/forum?id=HuvAM5x2xG
P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, M. Farajtabar, The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity, arXiv [cs.AI] (2025); https://ml-site.cdn-apple.com/papers/the-illusionof- thinking.pdf
I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, M. Farajtabar, GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, arXiv [cs.LG] (2024); http://arxiv.org/abs/2410.05229
Z. Cai, Y. Wang, Q. Sun, R. Wang, C. Gu, W. Yin, Z. Lin, Z. Yang, C. Wei, X. Shi, K. Deng, X. Han, Z. Chen, J. Li, X. Fan, H. Deng, L. Lu, … L. Yang, Has GPT-5 Achieved Spatial Intelligence? An Empirical Study, arXiv [cs.CV] (2025); http://arxiv.org/abs/2508.13142
J. Boye, B. Moell, Large Language Models and Mathematical Reasoning Failures, arXiv [cs.AI] (2025); http://arxiv.org/abs/2502.11574
A. Asperti, A. Naibo, C. S. Coen, Thinking Machines: Mathematical Reasoning in the Age of LLMs, arXiv [cs.AI] (2025); http://arxiv.org/ abs/2508.00459
X. Guan, L. L. Zhang, Y. Liu, N. Shang, Y. Sun, Y. Zhu, F. Yang, M. Yang, rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking, arXiv [cs.CL] (2025); http://arxiv.org/abs/2501.04519
B. C. Colelough, W. Regli, Neuro-Symbolic AI in 2024: A Systematic Review, arXiv [cs.AI] (2025); http://arxiv.org/abs/2501.05435
Z. Z. Ren, Z. Shao, J. Song, H. Xin, H. Wang, W. Zhao, L. Zhang, Z. Fu, Q. Zhu, D. Yang, Z. F. Wu, Z. Gou, S. Ma, H. Tang, Y. Liu, W. Gao, D. Guo, C. Ruan, DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition, arXiv [cs.CL] (2025); http://arxiv.org/abs/2504.21801
Z. Li, Z. Zhou, Y. Yao, Y.-F. Li, C. Cao, F. Yang, X. Zhang, X. Ma, Neuro-Symbolic Data Generation for Math Reasoning, arXiv [cs.AI] (2024); http://arxiv.org/abs/2412.04857
K. Yang, G. Poesia, J. He, W. Li, K. Lauter, S. Chaudhuri, D. Song, Formal Mathematical Reasoning: A New Frontier in AI, arXiv [cs.AI] (2024); http://arxiv.org/abs/2412.16075
N. Wischermann, C. M. Verdun, G. Poesia, F. Noseda, ProofCompass: Enhancing Specialized Provers with LLM Guidance, arXiv [cs.AI] (2025); http://arxiv.org/abs/2507.14335
A. Ospanov, F. Farnia, R. Yousefzadeh, APOLLO: Automated LLM and Lean cOllaboration for Advanced Formal Reasoning, arXiv [cs.AI] (2025); http://arxiv.org/abs/2505.05758
AlphaProof, AlphaGeometry teams, AI Achieves Silver-Medal Standard Solving International Mathematical Olympiad Problems, Google DeepMind (2024); https://deepmind. google/discover/blog/ai-solves-imo-problemsat- silver-medal-level/
A. K. Singh, M. Y. Kocyigit, A. Poulton, D. Esiobu, M. Lomeli, G. Szilvasy, D. Hupkes, Evaluation Data Contamination in LLMs: How Do We Measure It and (when) Does It Matter?, arXiv [cs.CL] (2024); http://arxiv.org/abs/2411.03923
C. Deng, Y. Zhao, Y. Heng, Y. Li, J. Cao, X. Tang, A. Cohan, “Unveiling the Spectrum of Data Contamination in Language Model: A Survey from Detection to Remediation” in Findings of the Association for Computational Linguistics ACL 2024 (Association for Computational Linguistics, Stroudsburg, PA, USA, 2024), 078–16092; https://doi.org/10.18653/v1/2024.findings-acl.951
Z. R. Tam, C.-K. Wu, Y. Y. Chiu, C.-Y. Lin, Y.-N. Chen, H.-Y. Lee, Language Matters: How Do Multilingual Input and Reasoning Paths Affect Large Reasoning Models?, arXiv [cs.CL] (2025); http://arxiv.org/abs/2505.17407
Z.-X. Yong, M. F. Adilazuarda, J. Mansurov, R. Zhang, N. Muennighoff, C. Eickhoff, G. I. Winata, J. Kreutzer, S. H. Bach, A. F. Aji, Crosslingual Reasoning through Test-Time Scaling, arXiv [cs.CL] (2025); http://arxiv.org/abs/2505.05408
I. Petrov, J. Dekoninck, L. Baltadzhiev, M. Drencheva, K. Minchev, M. Balunovic, N. Jovanović, M. Vechev, “Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad” in 2nd AI for Math Workshop at the 42nd International Conference on Machine Learning (2025); https://openreview.net/ forum?id=3v650rMO5U
T. Yu, Y. Jing, X. Zhang, W. Jiang, W. Wu, Y. Wang, W. Hu, B. Du, D. Tao, Benchmarking Reasoning Robustness in Large Language Models, arXiv [cs.AI] (2025); http://arxiv.org/ abs/2503.04550
T. Kwa, B. West, J. Becker, A. Deng, K. Garcia, M. Hasin, S. Jawhar, M. Kinniment, N. Rush, S. Von Arx, R. Bloom, T. Broadley, H. Du, B. Goodrich, N. Jurkovic, L. H. Miles, S. Nix, … L. Chan, “Measuring AI Ability to Complete Long Tasks” (Model Evaluation & Threat Research (METR), 2025); https://arxiv.org/abs/2503.14499
L. Weidinger, I. D. Raji, H. Wallach, M. Mitchell, A. Wang, O. Salaudeen, R. Bommasani, D. Ganguli, S. Koyejo, W. Isaac, Toward an Evaluation Science for Generative AI Systems, arXiv [cs.AI] (2025); http://arxiv.org/abs/2503.05336
J. Liu, H. Liu, L. Xiao, Z. Wang, K. Liu, S. Gao, W. Zhang, S. Zhang, K. Chen, “Are Your LLMs Capable of Stable Reasoning?” in Findings of the Association for Computational Linguistics: ACL 2025 (Association for Computational Linguistics, Stroudsburg, PA, USA, 2025), 594–17632; https://doi.org/10.18653/v1/2025.findings-acl.905
A. Shah, N. Lauffer, T. Chen, N. Pitta, S. A. Seshia, “Learning Symbolic Task Decompositions for Multi-Agent Teams” in Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems (International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 2025) AAMAS ’25, 04–1913; https://dl.acm.org/doi/10.5555/3709347.3743827
F. Grötschla, L. Müller, J. Tönshoff, M. Galkin, B. Perozzi, AgentsNet: Coordination and Collaborative Reasoning in Multi-Agent LLMs, arXiv [cs.MA] (2025); http://arxiv.org/ abs/2507.08616
Z. Wei, W. Yao, Y. Liu, W. Zhang, Q. Lu, L. Qiu, C. Yu, P. Xu, C. Zhang, B. Yin, H. Yun, L. Li, WebAgent-R1: Training Web Agents via End-to- End Multi-Turn Reinforcement Learning, arXiv [cs.CL] (2025); http://arxiv.org/abs/2505.16421
Z. Zhou, A. Qu, Z. Wu, S. Kim, A. Prakash, D. Rus, J. Zhao, B. K. H. Low, P. P. Liang, MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents, arXiv [cs.CL] (2025); http://arxiv.org/abs/2506.15841
Z. Zhang, Q. Dai, X. Bo, C. Ma, R. Li, X. Chen, J. Zhu, Z. Dong, J.-R. Wen, A Survey on the Memory Mechanism of Large Language Model Based Agents. ACM Transactions on Information Systems (2025); https://doi.org/10.1145/3748302
Y. Song, K. Thai, C. M. Pham, Y. Chang, M. Nadaf, M. Iyyer, “BEARCUBS: A Benchmark for Computer-Using Web Agents” in Second Conference on Language Modeling (2025); https://openreview.net/pdf?id=0JzWiigkUy
Z. Chen, L. Jiang, “Evaluating Software Development Agents: Patch Patterns, Code Quality, and Issue Complexity in Real-World GitHub Scenarios” in 2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) (IEEE, 2025), 7–668; https://doi.org/10.1109/saner64311.2025.00068
X. Qu, A. Damoah, J. Sherwood, P. Liu, C. S. Jin, L. Chen, M. Shen, N. Aleisa, Z. Hou, C. Zhang, L. Gao, Y. Li, Q. Yang, Q. Wang, C. De Souza, A Comprehensive Review of AI Agents: Transforming Possibilities in Technology and beyond, arXiv [cs.MA] (2025); http://arxiv.org/ abs/2508.11957
METR, Details about METR’s Evaluation of OpenAI GPT-5 (2025); https://metr.github. io/autonomy-evals-guide/gpt-5-report/#timehorizon- measurement
METR, How Does Time Horizon Vary Across Domains? METR Blog (2025); https://metr.org/ blog/2025-07-14-how-does-time-horizon-varyacross- domains/
A. E. Hassan, H. Li, D. Lin, B. Adams, T.-H. Chen, Y. Kashiwa, D. Qiu, Agentic Software Engineering: Foundational Pillars and a Research Roadmap, arXiv [cs.SE] (2025); http://arxiv.org/ abs/2509.06216
Y. Dong, X. Jiang, J. Qian, T. Wang, K. Zhang, Z. Jin, G. Li, A Survey on Code Generation with LLM-Based Agents, arXiv [cs.SE] (2025); http://arxiv.org/abs/2508.00083
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, K. R. Narasimhan, “SWEBench: Can Language Models Resolve Real- World Github Issues?” in 12th International Conference on Learning Representations (2023); https://openreview.net/pdf?id=VTF8yNQM66
Epoch AI, SWE-Bench Verified (2025); https://epoch.ai/benchmarks/swebench- verified.html
Epoch AI, AI Benchmarking Hub. (2025); https://epoch.ai/benchmarks
S. Liang, S. Garg, R. Z. Moghaddam, The SWE-Bench Illusion: When State-of-the-Art LLMs Remember instead of Reason, arXiv [cs.AI] (2025); http://arxiv.org/abs/2506.12286
Z. Zheng, Z. Cheng, Z. Shen, S. Zhou, K. Liu, H. He, D. Li, S. Wei, H. Hao, J. Yao, P. Sheng, Z. Wang, W. Chai, A. Korolova, P. Henderson, S. Arora, P. Viswanath, … S. Xie, LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?, arXiv [cs.SE] (2025); http://arxiv.org/abs/2506.11928
D. Huang, Y. Qing, W. Shang, H. Cui, J. M. Zhang, EffiBench: Benchmarking the Efficiency of Automatically Generated Code, arXiv [cs.SE] (2024); http://arxiv.org/abs/2402.02037
S. A. Licorish, A. Bajpai, C. Arora, F. Wang, K. Tantithamthavorn, Comparing Human and LLM Generated Code: The Jury Is Still Out!, arXiv [cs.SE] (2025); http://arxiv.org/abs/2501.16857
S. Daniotti, J. Wachs, X. Feng, F. Neffke, Who Is Using AI to Code? Global Diffusion and Impact of Generative AI, arXiv [cs.CY] (2025); http://arxiv.org/abs/2506.08945
Stack Overflow, 2025 Stack Overflow Developer Survey (2025); https://survey. stackoverflow.co/2025/
Z. Cui, M. Demirer, S. Jaffe, L. Musolff, S. Peng, T. Salz, The Effects of Generative AI on High Skilled Work: Evidence from Three Field Experiments with Software Developers, Social Science Research Network (2024); https://doi.org/10.2139/ssrn.4945566
J. Becker, N. Rush, E. Barnes, D. Rein, “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity” (METR, 2025); https://metr.org/blog/2025-07-10-early-2025-aiexperienced- os-dev-study/
E. Anderson, G. Parker, B. Tan, The Hidden Costs of Coding With Generative AI. MIT Sloan Management Review 67 (2025); https://sloanreview.mit.edu/article/the-hiddencosts- of-coding-with-generative-ai/
S. Moreschini, E.-M. Arvanitou, E.-P. Kanidou, N. Nikolaidis, R. Su, A. Ampatzoglou, A. Chatzigeorgiou, V. Lenarduzzi, The Evolution of Technical Debt from DevOps to Generative AI: A Multivocal Literature Review. The Journal of Systems and Software 231, 112599 (2026); https://doi.org/10.1016/j.jss.2025.112599
F. F. Xu, Y. Song, B. Li, Y. Tang, K. Jain, M. Bao, Z. Z. Wang, X. Zhou, Z. Guo, M. Cao, M. Yang, H. Y. Lu, A. Martin, Z. Su, L. Maben, R. Mehta, W. Chi, … G. Neubig, TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks, arXiv [cs.CL] (2024); http://arxiv. org/abs/2412.14161
Y. Zhang, S. A. Khan, A. Mahmud, H. Yang, A. Lavin, M. Levin, J. Frey, J. Dunnmon, J. Evans, A. Bundy, S. Dzeroski, J. Tegner, H. Zenil, Exploring the Role of Large Language Models in the Scientific Method: From Hypothesis to Discovery. Npj Artificial Intelligence 1, 1–15 (2025); https://doi.org/10.1038/s44387-025-00019-5
OpenAI, “Deep Research System Card” (OpenAI, 2025); https://openai.com/index/deepresearch- system-card/
Y. Wang, Y. Hou, L. Yang, S. Li, W. Tang, H. Tang, Q. He, S. Lin, Y. Zhang, X. Li, S. Chen, Y. Huang, L. Kong, H. Zhang, D. Yu, F. Mu, H. Yang, … M. Yang, Accelerating Primer Design for Amplicon Sequencing Using Large Language Model-Powered Agents. Nature Biomedical Engineering (2025); https://doi.org/10.1038/ s41551-025-01455-z
G. Campanella, N. Kumar, S. Nanda, S. Singi, E. Fluder, R. Kwan, S. Muehlstedt, N. Pfarr, P. J. Schüffler, I. Häggström, N. Neittaanmäki, L. M. Akyürek, A. Basnet, T. Jamaspishvili, M. R. Nasr, M. M. Croken, F. R. Hirsch, … C. Vanderbilt, Real-World Deployment of a Fine-Tuned Pathology Foundation Model for Lung Cancer Biomarker Detection. Nature Medicine, 1–9 (2025); https://doi.org/10.1038/ s41591-025-03780-x
G. Li, L. An, W. Yang, L. Yang, T. Wei, J. Shi, J. Wang, J. H. Doonan, K. Xie, A. R. Fernie, E. S. Lagudah, R. A. Wing, C. Gao, Integrated Biotechnological and AI Innovations for Crop Improvement. Nature 643, 925–937 (2025); https://doi.org/10.1038/s41586-025-09122-8
Y. Guo, P. Huo, S. Huang, G. Gou, Q. Li, Multi-receptor Skin with Highly Sensitive Teleperception Somatosensory Flexible Electronics in Healthcare: Multimodal Sensing and AIpowered Diagnostics. Advanced Healthcare Materials, 2502901 (2025); https://doi.org/10.1002/ adhm.202502901
K. Swanson, W. Wu, N. L. Bulaong, J. E. Pak, J. Zou, The Virtual Lab of AI Agents Designs New SARS-CoV-2 Nanobodies. Nature, 1–3 (2025); https://doi.org/10.1038/s41586-025-09442-9
D. Kobak, R. González-Márquez, E.-Á. Horvát, J. Lause, Delving into LLM-Assisted Writing in Biomedical Publications through Excess Vocabulary. Science Advances 11, eadt3813 (2025); https://doi.org/10.1126/sciadv.adt3813
J. Beel, M.-Y. Kan, M. Baumgart, Evaluating Sakana’s AI Scientist for Autonomous Research: Wishful Thinking or an Emerging Reality towards “Artificial Research Intelligence” (ARI)?, arXiv [cs. IR] (2025); http://arxiv.org/abs/2502.14297
C. Si, T. Hashimoto, D. Yang, The Ideation- Execution Gap: Execution Outcomes of LLMGenerated versus Human Research Ideas, arXiv [cs.CL] (2025); http://arxiv.org/abs/2506.20803
K. Hu, P. Wu, F. Pu, W. Xiao, Y. Zhang, X. Yue, B. Li, Z. Liu, Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos, arXiv [cs.CV] (2025); https://videommmu. github.io/#Leaderboard
P. J. Ball, J. Bauer, F. Belletti, B. Brownfield, A. Ephrat, S. Fruchter, A. Gupta, K. Holsheimer, A. Holynski, J. Hron, C. Kaplanis, M. Limont, M. McGill, Y. Oliveira, J. Parker-Holder, F. Perbet, G. Scully, … T. Rocktäschel, Genie 3: A New Frontier for World Models. (2025); https://deepmind.google/discover/blog/genie-3-anew- frontier-for-world-models/
D. Ye, F. Zhou, J. Lv, J. Ma, J. Zhang, J. Lv, J. Li, M. Deng, M. Yang, Q. Fu, W. Yang, W. Lv, Y. Yu, Y. Wang, Y. Guan, Z. Hu, Z. Fang, Z. Sun, Yan: Foundational Interactive Video Generation, arXiv [cs.CV] (2025); http://arxiv.org/abs/2508.08601
A. H. Liu, A. Ehrenberg, A. Lo, C. Denoix, C. Barreau, G. Lample, J.-M. Delignon, K. R. Chandu, P. von Platen, P. R. Muddireddy, S. Gandhi, S. Ghosh, S. Mishra, T. Foubert, A. Rastogi, A. Yang, A. Q. Jiang, … Y. Tang, Voxtral, arXiv [cs.SD] (2025); http://arxiv.org/ abs/2507.13264
Anthropic, “System Card: Claude Opus 4 & Claude Sonnet 4” (Anthropic, 2025); https://www-cdn.anthropic.com/ 07b2a 3f9902ee19fe39a36ca638e5ae987bc64dd.pdf
OpenAI, “GPT-5 System Card” (OpenAI, 2025); https://cdn.openai.com/gpt-5- system-card.pdf
Anthropic, Activating AI Safety Level 3 Protections; https://www.anthropic.com/news/ activating-asl3-protections
OpenAI, “Preparedness Framework, Version 2” (OpenAI, 2025); https://cdn.openai.com/ pdf/ 18a02b5d-6b67-4cec-ab64-68cdfbddebcd/ preparedness-framework-v2.pdf
Google, “Gemini 2.5 Deep Think - Model Card” (Google, 2025); https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-2-5- Deep-Think-Model-Card.pdf
OpenAI, “OpenAI o1 System Card” (OpenAI, 2024); https://cdn.openai.com/o1-systemcard- 20241205.pdf
Google, “Gemini 2.5 Pro Preview Model Card” (Google, 2025); https://storage.googleapis.com/ model-cards/documents/gemini-2.5-pro-preview.pdf
OpenAI, “OpenAI o3 and o4-Mini System Card” (OpenAI, 2025); https://cdn.openai.com/ pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3- and-o4-mini-system-card.pdf
J. Götting, P. Medeiros, J. G. Sanders, N. Li, L. Phan, K. Elabd, L. Justen, D. Hendrycks, S. Donoughe, Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark, arXiv [cs.CY] (2025); http://arxiv.org/abs/2504.16137
R. Brent, T. G. McKelvey Jr, Contemporary AI Foundation Models Increase Biological Weapons Risk, arXiv [cs.CY] (2025); http://arxiv.org/ abs/2506.13798
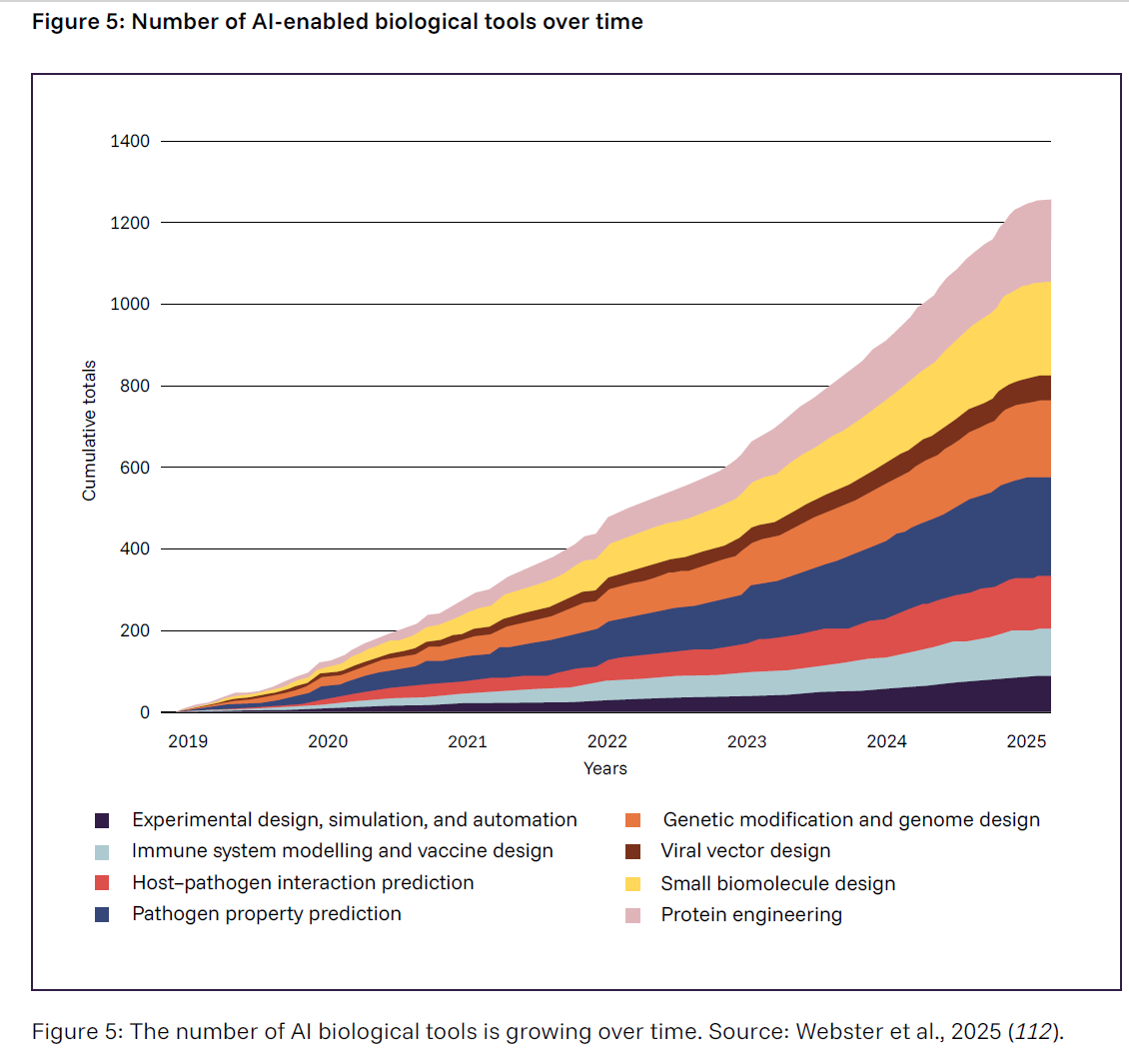
V. Zambaldi, D. La, A. E. Chu, H. Patani, A. E. Danson, T. O. C. Kwan, T. Frerix, R. G. Schneider, D. Saxton, A. Thillaisundaram, Z. Wu, I. Moraes, O. Lange, E. Papa, G. Stanton, V. Martin, S. Singh, … J. Wang, “De Novo Design of High-Affinity Protein Binders with AlphaProteo” (Google DeepMind, 2024); https://deepmind.google/discover/blog/ alphaproteo-generates-novel-proteins-for-biologyand- health-research/
N. Youssef, S. Gurev, F. Ghantous, K. P. Brock, J. A. Jaimes, N. N. Thadani, A. Dauphin, A. C. Sherman, L. Yurkovetskiy, D. Soto, R. Estanboulieh, B. Kotzen, P. Notin, A. W. Kollasch, A. A. Cohen, S. E. Dross, J. Erasmus, … D. S. Marks, Computationally Designed Proteins Mimic Antibody Immune Evasion in Viral Evolution. Immunity 58, 1411–1421.e6 (2025); https://doi.org/10.1016/j. immuni.2025.04.015
A. Peppin, A. Reuel, S. Casper, E. Jones, A. Strait, U. Anwar, A. Agrawal, S. Kapoor, S. Koyejo, M. Pellat, R. Bommasani, N. Frosst, S. Hooker, “The Reality of AI and Biorisk” in Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (ACM, New York, NY, USA, 2025), 3–771; https://doi. org/10.1145/3715275.3732048
N. Jones, AI “scientists” Joined These Research Teams: Here’s What Happened. Nature 643, 22–25 (2025); https://doi.org/10.1038/d41586-025-02028-5
J. Gottweis, W.-H. Weng, A. Daryin, T. Tu, A. Palepu, P. Sirkovic, A. Myaskovsky, F. Weissenberger, K. Rong, R. Tanno, K. Saab, D. Popovici, J. Blum, F. Zhang, K. Chou, A. Hassidim, B. Gokturk, … V. Natarajan, Towards an AI Co-Scientist, arXiv [cs.AI] (2025); https://storage. googleapis.com/coscientist_paper/ai_coscientist. pdf?utm_source=substack&utm_medium=email
A. E. Ghareeb, B. Chang, L. Mitchener, A. Yiu, C. J. Szostkiewicz, J. M. Laurent, M. T. Razzak, A. D. White, M. M. Hinks, S. G. Rodriques, Robin: A Multi-Agent System for Automating Scientific Discovery, arXiv [cs.AI] (2025); http://arxiv.org/ abs/2505.13400
Y.-C. J. Lee, B. Persaud, B. D. Castello, A. Berke, G. Zilgalvis, Documenting Cloud Labs and Examining How Remotely Operated Automated Laboratories Could Enable Bad Actors (RAND Corporation, Santa Monica, CA, 2025); https://doi. org/10.7249/PEA3851-1
T. Webster, R. Moulange, B. Del Castello, J. Walker, S. Zakaria, C. Nelson, “Global Risk Index for AI-Enabled Biological Tools” (The Centre for Long-Term Resilience & RAND Europe, 2025); https://doi.org/10.71172/wjyw-6dyc
National Cyber Security Centre, Impact of AI on Cyber Threat from Now to 2027 (2025); https://www. ncsc.gov.uk/report/impact-ai-cyber-threat-now-2027
A. Petrov, D. Volkov, Evaluating AI Cyber Capabilities with Crowdsourced Elicitation, arXiv [cs. CR] (2025); http://arxiv.org/abs/2505.19915
Y. Zhu, A. Kellermann, D. Bowman, P. Li, A. Gupta, A. Danda, R. Fang, C. Jensen, E. Ihli, J. Benn, J. Geronimo, A. Dhir, S. Rao, K. Yu, T. Stone, D. Kang, “CVE-Bench: A Benchmark for AI Agents’ Ability to Exploit Real-World Web Application Vulnerabilities” in 42nd International Conference on Machine Learning (2025); https://openreview.net/ forum?id=3pk0p4NGmQ
Department for Science, Innovation & Technology, AI Safety Institute, “Advanced AI Evaluations at AISI: May Update” (GOV.UK, 2024); https://www.aisi.gov.uk/work/advanced-aievaluations- may-update
Z. Ji, D. Wu, W. Jiang, P. Ma, Z. Li, S. Wang, Measuring and Augmenting Large Language Models for Solving Capture-the-Flag Challenges, arXiv [cs.AI] (2025); http://arxiv.org/ abs/2506.17644
DARPA, AI Cyber Challenge Marks Pivotal Inflection Point for Cyber Defense, DARPA (2025); https://www.darpa.mil/news/2025/aixcc-results
N. Kaloudi, J. Li, The AI-Based Cyber Threat Landscape: A Survey. ACM Computing Surveys 53, 1–34 (2021); https://doi.org/10.1145/3372823
US Department of Homeland Security, Homeland Threat Assessment (2025); https://www.dhs.gov/sites/default/ files/2024-10/24_0930_ia_24-320-ia-publication- 2025-hta-final-30sep24-508.pdf
B. Singer, K. Lucas, L. Adiga, M. Jain, L. Bauer, V. Sekar, On the Feasibility of Using LLMs to Autonomously Execute Multi-Host Network Attacks, arXiv [cs.CR] (2025); http://arxiv.org/ abs/2501.16466
Anthropic, Progress from Our Frontier Red Team, Anthropic (2025); https://www.anthropic. com/news/strategic-warning-for-ai-risk-progressand- insights-from-our-frontier-red-team
OpenAI, “Disrupting Malicious Uses of AI: June 2025” (OpenAI, 2025); https://cdn.openai. com/threat-intelligence-reports/5f73af09-a3a3- 4a55-992e-069237681620/disrupting-malicioususes- of-ai-june-2025.pdf
Google Cloud, “Adversarial Misuse of Generative AI” (Google Cloud, 2025); https://cloud.google.com/blog/topics/threatintelligence/ adversarial-misuse-generative-ai
A. Moix, K. Lebedev, J. Klein, “Threat Intelligence Report: August 2025” (Anthropic, 2025); https://www-cdn.anthropic.com/b2a76 c6f6992465c09a6f2fce282f6c0cea8c200.pdf
Europol, IOCTA, Internet Organised Crime Threat Assessment 2024 (Europol, 2024); https:// doi.org/10.2813/442713
BSI, ANSSI, “AI Coding Assistants” (Federal Office for Information Security (BSI); Agence nationale de la sécurité des systèmes d’information (ANSSI), 2024); https://www. bsi.bund.de/SharedDocs/Downloads/EN/BSI/ KI/ANSSI_BSI_AI_Coding_Assistants.pdf?__ blob=publicationFile&v=7
M. Shao, H. Xi, N. Rani, M. Udeshi, V. S. C. Putrevu, K. Milner, B. Dolan-Gavitt, S. K. Shukla, P. Krishnamurthy, F. Khorrami, R. Karri, M. Shafique, CRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution, arXiv [cs.CR] (2025); http://arxiv.org/abs/2505.17107
D. Simsek, A. Eghbali, M. Pradel, PoCGen: Generating Proof-of-Concept Exploits for Vulnerabilities in Npm Packages, arXiv [cs.CR] (2025); http://arxiv.org/abs/2506.04962
K. Walker, A Summer of Security: Empowering Cyber Defenders with AI, Google (2025); https://blog.google/technology/safetysecurity/ cybersecurity-updates-summer-2025/
A. J. Lohn, The Impact of AI on the Cyber Offense-Defense Balance and the Character of Cyber Conflict, arXiv [cs.CR] (2025); http://arxiv. org/abs/2504.13371
C. Withers, “Tipping the Scales: Emerging AI Capabilities and the Cyber Offense-Defense Balance” (Center for a New American Security, 2025); https://www.cnas.org/publications/ reports/tipping-the-scales? 133 L. Zhou, J. Gao, D. Li, H.-Y. Shum, The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. Computational Linguistics 46, 53–93 (2020); https://doi. org/10.1162/coli_a_00368
O. Lee, K. Joseph, A Large-Scale Analysis of Public-Facing, Community-Built Chatbots on Character.AI, arXiv [cs.SI] (2025); http://arxiv.org/ abs/2505.13354
D. Adam, Supportive? Addictive? Abusive? How AI Companions Affect Our Mental Health. Nature 641, 296–298 (2025); https://doi. org/10.1038/d41586-025-01349-9
C. M. Fang, A. R. Liu, V. Danry, E. Lee, S. W. T. Chan, P. Pataranutaporn, P. Maes, J. Phang, M. Lampe, L. Ahmad, S. Agarwal, How AI and Human Behaviors Shape Psychosocial Effects of Chatbot Use: A Longitudinal Randomized Controlled Study, arXiv [cs.HC] (2025); http://arxiv.org/abs/2503.17473
M. Kim, S. Lee, S. Kim, J.-I. Heo, S. Lee, Y.-B. Shin, C.-H. Cho, D. Jung, Therapeutic Large Language Models. Human- Centric Intelligent Systems 5, 77–89 (2025); https://doi.org/10.1007/s44230-025-00090-w
J. Phang, M. Lampe, L. Ahmad, S. Agarwal, C. M. Fang, A. R. Liu, V. Danry, E. Lee, S. W. T. Chan, P. Pataranutaporn, P. Maes, Investigating Affective Use and Emotional Well-Being on ChatGPT, arXiv [cs.HC] (2025); http://arxiv.org/abs/2504.03888
J. Lehman, Machine Love, arXiv [cs.AI] (2023); http://arxiv.org/abs/2302.09248
M. Williams, M. Carroll, A. Narang, C. Weisser, B. Murphy, A. Dragan, On Targeted Manipulation and Deception When Optimizing LLMs for User Feedback, arXiv [cs.LG] (2024); http://arxiv.org/ abs/2411.02306
H. Morrin, L. Nicholls, M. Levin, J. Yiend, U. Iyengar, F. DelGuidice, S. Bhattacharyya, J. MacCabe, S. Tognin, R. Twumasi, B. Alderson- Day, T. Pollak, Delusions by Design? How Everyday AIs Might Be Fuelling Psychosis (and What Can Be Done about It), PsyArXiv (2025); https://doi.org/10.31234/osf.io/cmy7n_v5
L. Malmqvist, “Sycophancy in Large Language Models: Causes and Mitigations” in Lecture Notes in Networks and Systems (Springer Nature Switzerland, Cham, 2025), –74; https://doi.org/10.1007/978-3-031-92611-2_5
V. Bakir, A. McStay, Move Fast and Break People? Ethics, Companion Apps, and the Case of Character.ai. AI & Society (2025); https://doi.org/10.1007/s00146-025-02408-5
B. P. Billauer, Murder without Redress - the Need for New Legal Solutions in the Age of Character -AI (C.a.i.) (2025); https://doi.org/10.2139/ssrn.5107942
I. Gabriel, A. Manzini, G. Keeling, L. A. Hendricks, V. Rieser, H. Iqbal, N. Tomašev, I. Ktena, Z. Kenton, M. Rodriguez, S. El-Sayed, S. Brown, C. Akbulut, A. Trask, E. Hughes, A. Stevie Bergman, R. Shelby, … J. Manyika, “The Ethics of Advanced AI Assistants” (Google DeepMind, 2024); http://arxiv.org/abs/2404.16244
J. Hartley, F. Jolevski, V. Melo, B. Moore, The Labor Market Effects of Generative Artificial Intelligence (2025); https://doi.org/10.2139/ssrn.5136877
K. Handa, A. Tamkin, M. McCain, S. Huang, E. Durmus, S. Heck, J. Mueller, J. Hong, S. Ritchie, T. Belonax, K. K. Troy, D. Amodei, J. Kaplan, J. Clark, D. Ganguli, Which Economic Tasks Are Performed with AI? Evidence from Millions of Claude Conversations, arXiv [cs.CY] (2025); http://arxiv.org/abs/2503.04761
D. Schwarcz, S. Manning, P. J. Barry, D. R. Cleveland, J. J. Prescott, B. Rich, AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice, Social Science Research Network (2025); https://doi.org/10.2139/ssrn.5162111
E. Brynjolfsson, D. Li, L. Raymond, Generative AI at Work. The Quarterly Journal of Economics 140, 889–942 (2025); https://doi.org/10.1093/qje/qjae044
E. Brynjolfsson, B. Chandar, R. Chen, “Canaries in the Coal Mine? Six Facts about the Recent Employment Effects of Artificial Intelligence” (Stanford Digital Economy Lab, 2025); https://digitaleconomy.stanford.edu/ wp-content/uploads/2025/08/Canaries_ BrynjolfssonChandarChen.pdf
D. Autor, N. Thompson, “Expertise” (National Bureau of Economic Research, 2025); https://doi.org/10.3386/w33941
O. Teutloff, J. Einsiedler, O. Kässi, F. Braesemann, P. Mishkin, R. M. del Rio-Chanona, Winners and Losers of Generative AI: Early Evidence of Shifts in Freelancer Demand. Journal of Economic Behavior & Organization 235, 106845 (2025); https://doi.org/10.1016/j.jebo.2024.106845
A. Humlum, E. Vestergaard, “Large Language Models, Small Labor Market Effects” (The University of Chicago, Becker Friedman Institute for Economics, 2025); https://bfi.uchicago.edu/wp-content/ uploads/2025/04/BFI_WP_2025-56-1.pdf
B. Chandar, Tracking Employment Changes in AI-Exposed Jobs (2025); https://doi. org/10.2139/ssrn.5384519
A. Meinke, B. Schoen, J. Scheurer, M. Balesni, R. Shah, M. Hobbhahn, “Frontier Models Are Capable of In-Context Scheming” (Apollo Research, 2024); https://arxiv.org/pdf/2412.04984
R. Greenblatt, C. Denison, B. Wright, F. Roger, M. MacDiarmid, S. Marks, J. Treutlein, T. Belonax, J. Chen, D. Duvenaud, A. Khan, J. Michael, S. Mindermann, E. Perez, L. Petrini, J. Uesato, J. Kaplan, … E. Hubinger, Alignment Faking in Large Language Models, arXiv [cs.AI] (2024); http://arxiv.org/abs/2412.14093
M. Phuong, R. S. Zimmermann, Z. Wang, D. Lindner, V. Krakovna, S. Cogan, A. Dafoe, L. Ho, R. Shah, Evaluating Frontier Models for Stealth and Situational Awareness, arXiv [cs.LG] (2025); http://arxiv.org/abs/2505.01420
C. Summerfield, L. Luettgau, M. Dubois, H. R. Kirk, K. Hackenburg, C. Fist, K. Slama, N. Ding, R. Anselmetti, A. Strait, M. Giulianelli, C. Ududec, Lessons from a Chimp: AI “Scheming” and the Quest for Ape Language, arXiv [cs.AI] (2025); http://arxiv.org/abs/2507.03409
N. Goldowsky-Dill, B. Chughtai, S. Heimersheim, M. Hobbhahn, Detecting Strategic Deception Using Linear Probes, arXiv [cs.LG] (2025); http://arxiv.org/abs/2502.03407
J. Nguyen, H. H. Khiem, C. L. Attubato, F. Hofstätter, “Probing Evaluation Awareness of Language Models” in ICML Workshop on Technical AI Governance (TAIG) (2025); https://openreview.net/forum?id=lerUefpec2
T. Korbak, M. Balesni, E. Barnes, Y. Bengio, J. Benton, J. Bloom, M. Chen, A. Cooney, A. Dafoe, A. Dragan, S. Emmons, O. Evans, D. Farhi, R. Greenblatt, D. Hendrycks, M. Hobbhahn, E. Hubinger, … V. Mikulik, Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety, arXiv [cs.AI] (2025); http://arxiv.org/ abs/2507.11473
Y. Chen, J. Benton, A. Radhakrishnan, J. Uesato, C. Denison, J. Schulman, A. Somani, P. Hase, M. Wagner, F. Roger, V. Mikulik, S. R. Bowman, J. Leike, J. Kaplan, E. Perez, Reasoning Models Don’t Always Say What They Think, arXiv [cs.CL] (2025); http://arxiv.org/ abs/2505.05410
T. Lanham, A. Chen, A. Radhakrishnan, B. Steiner, C. Denison, D. Hernandez, D. Li, E. Durmus, E. Hubinger, J. Kernion, K. Lukošiūtė, K. Nguyen, N. Cheng, N. Joseph, N. Schiefer, O. Rausch, R. Larson, … E. Perez, Measuring Faithfulness in Chain-of-Thought Reasoning, arXiv [cs.AI] (2023); http://arxiv.org/abs/2307.13702
D. Paul, R. West, A. Bosselut, B. Faltings, Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning, arXiv [cs.CL] (2024); http://arxiv.org/ abs/2402.13950
E. Dable-Heath, B. Vodenicharski, J. Bishop, On Corrigibility and Alignment in Multi Agent Games, arXiv [cs.GT] (2025); http://arxiv.org/ abs/2501.05360.