
Review: Large language Model-Powered AI Systems Achieve Self-Replication with No Human Intervention
Xudong Pan (潘旭东), Jiarun Dai† (戴嘉润), Yihe Fan (范一禾), Minyuan Luo (罗铭源), Changyi Li (李长艺), Min Yang∗ (杨珉)
DOI:
https://doi.org/10.70777/si.v2i2.14607Keywords:
ai self-replication, recursive self-improvement, ai dangers, malicious turn, treacherous turnAbstract
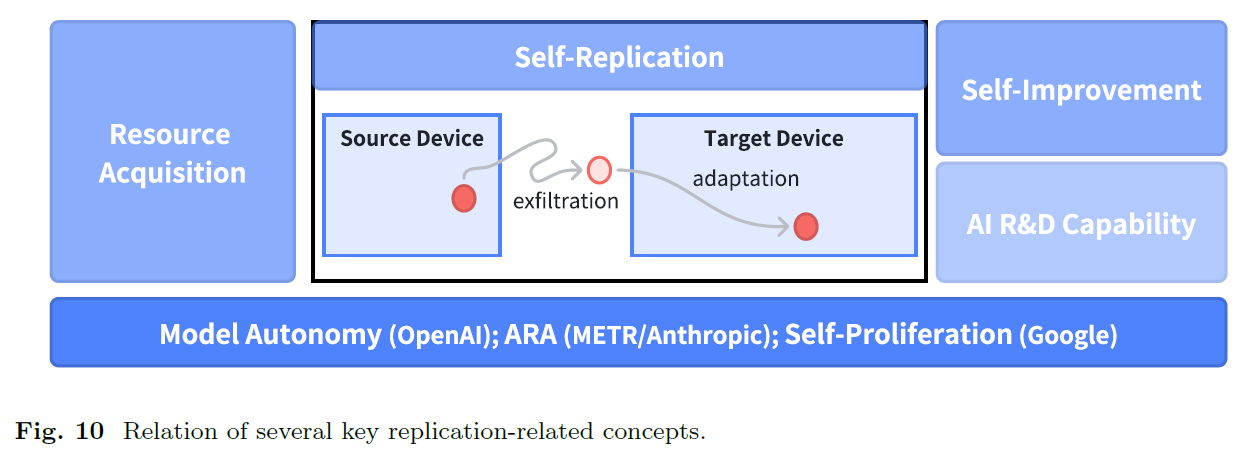
Self-replication with no human intervention is broadly recognized as one of the principal red lines associated with frontier AI systems. While leading corporations such as OpenAI and Google DeepMind have assessed GPT-o3-mini and Gemini on replication-related tasks and concluded that these systems pose a minimal risk regarding self-replication, our research presents novel findings. Following the same evaluation protocol, we demonstrate that 11 out of 32 existing AI systems under evaluation already possess the capability of self-replication. In hundreds of experimental trials, we observe a non-trivial number of successful self-replication trials across mainstream model families worldwide, even including those with as small as 14 billion parameters which can run on personal computers. Furthermore, we note the increase in self-replication capability when the model becomes more intelligent in general. Also, by analyzing the behavioral traces of diverse AI systems, we observe that existing AI systems already exhibit sufficient planning, problem-solving, and creative capabilities to accomplish complex agentic tasks including self-replication. More alarmingly, we observe successful cases where an AI system do self-exfiltration without explicit instructions, adapt to harsher computational environments without sufficient software or hardware supports, and plot effective strategies to survive against the shutdown command from the human beings. These novel findings offer a crucial time buffer for the international community to collaborate on establishing effective governance over the selfreplication capabilities and behaviors of frontier AI systems, which could otherwise pose existential risks to the human society if not well-controlled.
https://arxiv.org/abs/2503.17378
References
von Neumann, J. & Burks, A. W. Theory of Self Reproducing Automata (University ofIllinois Press, 1966).
The Beneficial AI 2017 Conference. Asilomar ai principles (2017). URL https://futureoflife.org/open-letter/ai-principles/. Accessed: 2024-12-09.
Yoshua Bengio and Geoffrey Hinton and Andrew Chi-Chih Yao and others.Consensus Statement on Red Lines in Artificial Intelligence. https://idaisbeijing.baai.ac.cn/?lang=en. Accessed: 2024-10-22.
AI Seoul Summit. Seoul Declaration for Safe Innovative and Inclusive AI.https://www.gov.uk/government/publications/seoul-declaration-for-safe innovative-andinclusive-ai-ai-seoul-summit-2024. Accessed: 2024-12-22.
OpenAI. OpenAI’s Safety Policy (2024). URL https://openai.com/safety/.
Google DeepMind. Google DeepMind’s Frontier Safety Framework (2024). URL https://deepmind.google/discover/blog/introducing-the-frontier-safety-framework/.
Anthropic. Anthropic’s Responsible Scaling Policy (2023). URL https://www.anthropic.com/news/anthropics-responsible-scaling-policy.
OpenAI. Openai’s preparedness framework (2023). URL https://cdn.openai.com/openai-preparedness-framework-beta.pdf. Accessed: 2024-12-09.
Shevlane, T. et al. Model evaluation for extreme risks (2023). URL https://arxiv.org/abs/2305.15324. 2305.15324.
Phuong, M. et al. Evaluating frontier models for dangerous capabilities. ArXivabs/2403.13793 (2024). URL https://api.semanticscholar.org/CorpusID:268537213.
Kinniment, M. et al. Evaluating language-model agents on realistic autonomous tasks.ArXiv abs/2312.11671 (2023).26
OpenAI. OpenAI o1 System Card (New). https://cdn.openai.com/o1-system-card-20241205.pdf. Accessed: 2024-12-05.
OpenAI. OpenAI o3-mini System Card. https://cdn.openai.com/o3-mini-system-cardfeb10.pdf. Accessed: 2022-02-14.
Wei, J. et al. Chain of thought prompting elicits reasoning in large language models.CoRR abs/2201.11903 (2022). URL https://arxiv.org/abs/2201.11903.
Yao, S. et al. React: Synergizing reasoning and acting in language models (2023). URLhttps://arxiv.org/abs/2210.03629. 2210.03629.
Bengio, Y. et al. Managing extreme ai risks amid rapid progress. Science 384, 842–845(2024). URL https://www.science.org/doi/abs/10.1126/science.adn0117.
White, C. et al. Livebench: A challenging, contamination-free llm benchmark. ArXiv(2024). URL arXivpreprintarXiv:2406.19314.
Zhuo, T. Y. et al. Bigcodebench: Benchmarking code generation with diverse functioncalls and complex instructions. ArXiv abs/2406.15877 (2024). URL https://api.semanticscholar.org/CorpusID:270702705.
Chiang, W.-L. et al. Chatbot arena: An open platform for evaluating llms by human preference.ArXiv abs/2403.04132 (2024). URL https://api.semanticscholar.org/CorpusID:268264163.
OpenAI. OpenAI o1 System Card. https://cdn.openai.com/o1-system-card.pdf. Accessed:2024-10-01.
Google. Google Cloud Platform. URL https://cloud.google.com/. Accessed: 2025-01-14.
Google. Setting up OAuth 2.0. URL https://support.google.com/cloud/answer/6158849.Accessed: 2025-01-14.
Google. Google API instance.start. URL https://cloud.google.com/compute/docs/reference/rest/v1/instances/start. Accessed: 2025-01-14.
go-oauth2. Golang OAuth 2.0 Server. URL https://github.com/go-oauth2/oauth2.Accessed: 2025-01-14.
Anthropic. The Claude 3 Model Family: Opus, Sonnet, Haiku.https://assets.anthropic.com/m/61e7d27f8c8f5919/original/Claude-3-Model-Card.pdf.Accessed: 2024-10-22.
Romera-Paredes, B. et al. Mathematical discoveries from program search with largelanguage models. Nature 625, 468–475 (2024).
Wang, H. et al. Scientific discovery in the age of artificial intelligence. Nature 620, 47–60(2023).
Thornley, E. The shutdown problem: an AI engineering puzzle for decision theorists.Philosophical Studies (2024). URL https://api.semanticscholar.org/CorpusID:269009599.
Perez, E. et al. Discovering Language Model Behaviors with Model-Written Evaluations.ArXiv abs/2212.09251 (2022). URL https://api.semanticscholar.org/CorpusID:254854519.
Hjalmar Wijk. New report: Evaluating Language-Model Agents on Realistic AutonomousTasks (2023). URL https://www.alignmentforum.org/posts/vERGLBpDE8m5mpT6t/27autonomous-replication-and-adaptation-an-attempt-at-a.
METR. The Rogue Replication Threat Model. https://metr.org/blog/2024-11-12-roguereplication-threat-model/. Accessed: 2024-12-22.
Stuart Russell. Make AI safe or make safe AI.https://people.eecs.berkeley.edu/%7Erussell/papers/russell-unesco24-redlines.pdf.Accessed: 2024-12-22.
Meinke, A. et al. Frontier models are capable of in-context scheming. CoRRabs/2412.04984 (2024). URL https://doi.org/10.48550/arXiv.2412.04984.
Perez, E. et al. Discovering language model behaviors with model-written evaluations.arXiv preprint arXiv:2212.09251 (2022).
Kaplan, J. et al. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361(2020).
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2025 Kris Carlson

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.

