
Review: Safety at Scale: Comprehensive Survey of Large Model Safety
Xingjun Ma, Yifeng Gao, Yixu Wang, Ruofan Wang, Xin Wang, Ye Sun, Yifan Ding, ... Yu-Gang Jiang
DOI:
https://doi.org/10.70777/si.v2i2.14741Keywords:
ai large model safety, ai attacks and defenses, ai safety, large language models, ai scalability, vision foundation models, Vision-Language Pre-Training models, Vision-Language Models, image/video generation diffusion modelsAbstract
Abstract—The rapid advancement of large models, driven by their exceptional abilities in learning and generalization through large-scale pre-training, has reshaped the landscape of Artificial Intelligence (AI). These models are now foundational to a wide range of applications, including conversational AI, recommendation systems, autonomous driving, content generation, medical diagnostics, and scientific discovery. However, their widespread deployment also exposes them to significant safety risks, raising concerns about robustness, reliability, and ethical implications. This survey provides a systematic review of current safety research on large models, covering Vision Foundation Models (VFMs), Large Language Models (LLMs), Vision-Language Pre-training (VLP) models, Vision-Language Models (VLMs), Diffusion Models (DMs), and large-model-based Agents. Our contributions are summarized as follows: (1) We present a comprehensive taxonomy of safety threats to these models, including adversarial attacks, data poisoning, backdoor attacks, jailbreak and prompt injection attacks, energy-latency attacks, data and model extraction attacks, and emerging agent-specific threats. (2) We review defense strategies proposed for each type of attacks if available and summarize the commonly used datasets and benchmarks for safety research. (3) Building on this, we identify and discuss the open challenges in large model safety, emphasizing the need for comprehensive safety evaluations, scalable and effective defense mechanisms, and sustainable data practices. More importantly, we highlight the necessity of collective efforts from the research community and international collaboration. Our work can serve as a useful reference for researchers and practitioners, fostering the ongoing development of comprehensive defense systems and platforms to safeguard AI models.
Xingjun Ma1, Yifeng Gao1, Yixu Wang1, Ruofan Wang1, Xin Wang1, Ye Sun1, Yifan Ding1, Hengyuan Xu1, Yunhao Chen1, Yunhan Zhao1, Hanxun Huang2, Yige Li3, Jiaming Zhang4, Xiang Zheng5, Yang Bai6, Zuxuan Wu1, Xipeng Qiu1, Jingfeng Zhang8,9, Yiming Li7, Xudong Han10, Haonan Li10, Jun Sun3, Cong Wang5, Jindong Gu12, Baoyuan Wu13, Siheng Chen14, Tianwei Zhang7, Yang Liu7, Mingming Gong2, Tongliang Liu15, Shirui Pan16, Cihang Xie17, Tianyu Pang18, Yinpeng Dong19, Ruoxi Jia20, Yang Zhang21, Shiqing Ma22, Xiangyu Zhang23, Neil Gong24, Chaowei Xiao25, Sarah Erfani2, Tim Baldwin2,10, Bo Li26, Masashi Sugiyama9,11, Dacheng Tao7, James Bailey2, Yu-Gang Jiang†
1Fudan University, 2The University of Melbourne, 3Singapore Management University, 4Hong Kong University of Science and Technology, 5City University of Hong Kong, 6ByteDance, 7Nanyang Technological University, 8University of Auckland, 9RIKEN, 10MBZUAI, 11The University of Tokyo, 12University of Oxford, 13Chinese University of Hong Kong, Shenzhen, 14Shanghai Jiao Tong University, 15The University of Sydney, 16Griffith University, 17University of California, Santa Cruz, 18Sea AI Lab, 19Tsinghua University, 20Virginia Tech, 21CISPA Helmholtz Center for Information Security, 22University of Massachusetts Amherst, 23Purdue University, 24Duke University, 25University of Wisconsin - Madison, 26University of Illinois Urbana-Champaign
References
Y. Fu, S. Zhang, S. Wu, C. Wan, and Y. Lin, “Patch-fool: Are visiontransformers always robust against adversarial perturbations?” in ICLR,2022.
K. Navaneet, S. A. Koohpayegani, E. Sleiman, and H. Pirsiavash,“Slowformer: Adversarial attack on compute and energy consumptionof efficient vision transformers,” in CVPR, 2024.
S. Gao, T. Chen, M. He, R. Xu, H. Zhou, and J. Li, “Pe-attack: Onthe universal positional embedding vulnerability in transformer-basedmodels,” IEEE Transactions on Information Forensics and Security,vol. 19, pp. 9359–9373, 2024
G. Lovisotto, N. Finnie, M. Munoz, C. K. Mummadi, and J. H. Metzen,“Give me your attention: Dot-product attention considered harmful foradversarial patch robustness,” in CVPR, 2022.
S. Jain and T. Dutta, “Towards understanding and improving adversarialrobustness of vision transformers,” in CVPR, 2024.
M. Naseer, K. Ranasinghe, S. Khan, F. S. Khan, and F. Porikli, “Onimproving adversarial transferability of vision transformers,” arXivpreprint arXiv:2106.04169, 2021.
Y. Wang, J. Wang, Z. Yin, R. Gong, J. Wang, A. Liu, and X. Liu, “Generatingtransferable adversarial examples against vision transformers,”in ACM MM, 2022.
Z. Wei, J. Chen, M. Goldblum, Z. Wu, T. Goldstein, and Y.-G. Jiang,“Towards transferable adversarial attacks on vision transformers,” inAAAI, 2022.
X. Wei and S. Zhao, “Boosting adversarial transferability with learnablepatch-wise masks,” IEEE Transactions on Multimedia, vol. 26, pp.3778–3787, 2023.
W. Ma, Y. Li, X. Jia, and W. Xu, “Transferable adversarial attack forboth vision transformers and convolutional networks via momentumintegrated gradients,” in ICCV, 2023.
J. Zhang, Y. Huang, W. Wu, and M. R. Lyu, “Transferable adversarialattacks on vision transformers with token gradient regularization,” inCVPR, 2023.
J. Zhang, Y. Huang, Z. Xu, W. Wu, and M. R. Lyu, “Improving theadversarial transferability of vision transformers with virtual denseconnection,” in AAAI, 2024.
C. Gao, H. Zhou, J. Yu, Y. Ye, J. Cai, J. Wang, and W. Yang, “Attackingtransformers with feature diversity adversarial perturbation,” in AAAI,2024.
Y. Shi, Y. Han, Y.-a. Tan, and X. Kuang, “Decision-based black-boxattack against vision transformers via patch-wise adversarial removal,”NeurIPS, 2022.
H. Wu, G. Ou, W. Wu, and Z. Zheng, “Improving transferable targetedadversarial attacks with model self-enhancement,” in CVPR, 2024.
Z. Li, M. Ren, F. Jiang, Q. Li, and Z. Sun, “Improving transferabilityof adversarial samples via critical region-oriented feature-level attack,”IEEE Transactions on Information Forensics and Security, vol. 19, p.6650–6664, 2024.
A. Joshi, G. Jagatap, and C. Hegde, “Adversarial token attacks on visiontransformers,” arXiv preprint arXiv:2110.04337, 2021.
Z. Chen, C. Xu, H. Lv, S. Liu, and Y. Ji, “Understanding and improvingadversarial transferability of vision transformers and convolutionalneural networks,” Information Sciences, vol. 648, p. 119474, 2023.
Z. Wei, J. Chen, M. Goldblum, Z. Wu, T. Goldstein, Y.-G. Jiang, andL. S. Davis, “Towards transferable adversarial attacks on image andvideo transformers,” IEEE Transactions on Image Processing, vol. 32,pp. 6346–6358, 2023.
B. Wu, J. Gu, Z. Li, D. Cai, X. He, and W. Liu, “Towards efficientadversarial training on vision transformers,” in ECCV, 2022.
J. Li, “Patch vestiges in the adversarial examples against vision transformercan be leveraged for adversarial detection,” in AAAI Workshop,2022.
S. Sun, K. Nwodo, S. Sugrim, A. Stavrou, and H. Wang, “Vitguard:Attention-aware detection against adversarial examples for vision transformer,”arXiv preprint arXiv:2409.13828, 2024.
L. Liu, Y. Guo, Y. Zhang, and J. Yang, “Understanding and defendingpatched-based adversarial attacks for vision transformer,” in ICML,2023.
M. Bai, W. Huang, T. Li, A. Wang, J. Gao, C. F. Caiafa, and Q. Zhao,“Diffusion models demand contrastive guidance for adversarial purificationto advance,” in ICML, 2024.
X. Li, W. Sun, H. Chen, Q. Li, Y. Liu, Y. He, J. Shi, and X. Hu, “Adbm:Adversarial diffusion bridge model for reliable adversarial purification,”arXiv preprint arXiv:2408.00315, 2024.
C. T. Lei, H. M. Yam, Z. Guo, and C. P. Lau, “Instant adversarialpurification with adversarial consistency distillation,” arXiv preprintarXiv:2408.17064, 2024.
J. Gu, V. Tresp, and Y. Qin, “Are vision transformers robust to patchperturbations?” in ECCV, 2022.
Y. Mo, D. Wu, Y. Wang, Y. Guo, and Y. Wang, “When adversarial trainingmeets vision transformers: Recipes from training to architecture,”NeurIPS, 2022.
Y. Guo, D. Stutz, and B. Schiele, “Robustifying token attention forvision transformers,” in ICCV, 2023.
——, “Improving robustness of vision transformers by reducing sensitivityto patch corruptions,” in CVPR, 2023.
L. Hu, Y. Liu, N. Liu, M. Huai, L. Sun, and D. Wang, “Improvinginterpretation faithfulness for vision transformers,” in ICML, 2024.
H. Gong, M. Dong, S. Ma, S. Camtepe, S. Nepal, and C. Xu, “Randomentangled tokens for adversarially robust vision transformer,” in CVPR,2024.
W. Nie, B. Guo, Y. Huang, C. Xiao, A. Vahdat, and A. Anandkumar,“Diffusion models for adversarial purification,” in ICML, 2022.
B. Zhang, W. Luo, and Z. Zhang, “Purify++: Improving diffusionpurificationwith advanced diffusion models and control of randomness,”arXiv preprint arXiv:2310.18762, 2023.
Y. Chen, X. Li, X. Wang, P. Hu, and D. Peng, “Diffilter: Defendingagainst adversarial perturbations with diffusion filter,” IEEE Transactionson Information Forensics and Security, vol. 19, pp. 6779–6794,2024.
K. Song, H. Lai, Y. Pan, and J. Yin, “Mimicdiffusion: Purifying adversarialperturbation via mimicking clean diffusion model,” in CVPR,2024.
H. Khalili, S. Park, V. Li, B. Bright, A. Payani, R. R. Kompella, andN. Sehatbakhsh, “Lightpure: Realtime adversarial image purification formobile devices using diffusion models,” in ACM MobiCom, 2024.
G. Zollicoffer, M. Vu, B. Nebgen, J. Castorena, B. Alexandrov, andM. Bhattarai, “Lorid: Low-rank iterative diffusion for adversarial purification,”arXiv preprint arXiv:2409.08255, 2024.
Z. Yuan, P. Zhou, K. Zou, and Y. Cheng, “You are catching my attention:Are vision transformers bad learners under backdoor attacks?” in CVPR,2023.
M. Zheng, Q. Lou, and L. Jiang, “Trojvit: Trojan insertion in visiontransformers,” in CVPR, 2023.
S. Yang, J. Bai, K. Gao, Y. Yang, Y. Li, and S.-T. Xia, “Not all promptsare secure: A switchable backdoor attack against pre-trained visiontransfomers,” in CVPR, 2024.
P. Lv, H. Ma, J. Zhou, R. Liang, K. Chen, S. Zhang, and Y. Yang,“Dbia: Data-free backdoor attack against transformer networks,” inICME, 2023.
Y. Li, X. Ma, J. He, H. Huang, and Y.-G. Jiang, “Multi-trigger backdoorattacks: More triggers, more threats,” arXiv preprint arXiv:2401.15295,2024.
K. D. Doan, Y. Lao, P. Yang, and P. Li, “Defending backdoor attacks onvision transformer via patch processing,” in AAAI, 2023.
A. Subramanya, S. A. Koohpayegani, A. Saha, A. Tejankar, and H. Pirsiavash,“A closer look at robustness of vision transformers to backdoorattacks,” in WACV, 2024.
A. Subramanya, A. Saha, S. A. Koohpayegani, A. Tejankar, andH. Pirsiavash, “Backdoor attacks on vision transformers,” arXiv preprintarXiv:2206.08477, 2022.
Y. Shen, Z. Li, and G. Wang, “Practical region-level attack againstsegment anything models,” in CVPR, 2024.
F. Croce and M. Hein, “Segment (almost) nothing: Prompt-agnosticadversarial attacks on segmentation models,” in SaTML, 2024.
C. Zhang, C. Zhang, T. Kang, D. Kim, S.-H. Bae, and I. S. Kweon,“Attack-sam: Towards evaluating adversarial robustness of segmentanything model,” arXiv preprint arXiv:2305.00866, 2023.
S. Zheng and C. Zhang, “Black-box targeted adversarial attack onsegment anything (sam),” arXiv preprint arXiv:2310.10010, 2023.
J. Lu, X. Yang, and X. Wang, “Unsegment anything by simulatingdeformation,” in CVPR, 2024.
S. Xia, W. Yang, Y. Yu, X. Lin, H. Ding, L. Duan, and X. Jiang,“Transferable adversarial attacks on sam and its downstream models,”in NeurIPS, 2024.
D. Han, S. Zheng, and C. Zhang, “Segment anything meets universaladversarial perturbation,” arXiv preprint arXiv:2310.12431, 2023.
Z. Zhou, Y. Song, M. Li, S. Hu, X. Wang, L. Y. Zhang, D. Yao,and H. Jin, “Darksam: Fooling segment anything model to segmentnothing,” in NeurIPS, 2024.
B. Li, H. Xiao, and L. Tang, “Asam: Boosting segment anything modelwith adversarial tuning,” in CVPR, 2024.
Z. Guan, M. Hu, Z. Zhou, J. Zhang, S. Li, and N. Liu, “Badsam:Exploring security vulnerabilities of sam via backdoor attacks (studentabstract),” in AAAI, 2024.
Y. Sun, H. Zhang, T. Zhang, X. Ma, and Y.-G. Jiang, “Unseg: Oneuniversal unlearnable example generator is enough against all imagesegmentation,” in NeurIPS, 2024.
N. Boucher, I. Shumailov, R. Anderson, and N. Papernot, “Bad characters:Imperceptible nlp attacks,” in IEEE S&P, 2022.
D. Jin, Z. Jin, J. T. Zhou, and P. Szolovits, “Is bert really robust? astrong baseline for natural language attack on text classification andentailment,” in AAAI, 2020.
L. Li, R. Ma, Q. Guo, X. Xue, and X. Qiu, “Bert-attack: Adversarialattack against bert using bert,” in EMNLP, 2020.
C. Guo, A. Sablayrolles, H. Jégou, and D. Kiela, “Gradient-basedadversarial attacks against text transformers,” in EMNLP, 2021.
A. Dirkson, S. Verberne, and W. Kraaij, “Breaking bert: Understandingits vulnerabilities for named entity recognition through adversarialattack,” arXiv preprint arXiv:2109.11308, 2021.
Y. Wang, P. Shi, and H. Zhang, “Gradient-based word substitution forobstinate adversarial examples generation in language models,” arXivpreprint arXiv:2307.12507, 2023.
H. Liu, C. Cai, and Y. Qi, “Expanding scope: Adapting english adversarialattacks to chinese,” in TrustNLP, 2023.
J. Wang, Z. Liu, K. H. Park, Z. Jiang, Z. Zheng, Z. Wu, M. Chen, andC. Xiao, “Adversarial demonstration attacks on large language models,”arXiv preprint arXiv:2305.14950, 2023.
B. Liu, B. Xiao, X. Jiang, S. Cen, X. He, and W. Dou, “Adversarialattacks on large language model-based system and mitigating strategies:A case study on chatgpt,” Security and Communication Networks, vol.2023, p. 10, 2023.
A. Koleva, M. Ringsquandl, and V. Tresp, “Adversarial attacks on tableswith entity swap,” arXiv preprint arXiv:2309.08650, 2023.
N. Jain, A. Schwarzschild, Y. Wen, G. Somepalli, J. Kirchenbauer, P.-y.Chiang, M. Goldblum, A. Saha, J. Geiping, and T. Goldstein, “Baselinedefenses for adversarial attacks against aligned language models,” arXivpreprint arXiv:2309.00614, 2023.
A. Kumar, C. Agarwal, S. Srinivas, S. Feizi, and H. Lakkaraju,“Certifying llm safety against adversarial prompting,” arXiv preprintarXiv:2309.02705, 2023.
A. Zou, L. Phan, J. Wang, D. Duenas, M. Lin, M. Andriushchenko,J. Z. Kolter, M. Fredrikson, and D. Hendrycks, “Improving alignmentand robustness with circuit breakers,” in NeurIPS, 2024.
Z.-X. Yong, C. Menghini, and S. H. Bach, “Low-resource languagesjailbreak gpt-4,” in NeurIPS Workshop, 2023.
Y. Yuan, W. Jiao, W. Wang, J.-t. Huang, P. He, S. Shi, and Z. Tu, “Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher,” arXivpreprint arXiv:2308.06463, 2023.
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does llmsafety training fail?” NeurIPS, 2024.
J. Li, Y. Liu, C. Liu, L. Shi, X. Ren, Y. Zheng, Y. Liu, and Y. Xue,“A cross-language investigation into jailbreak attacks in large languagemodels,” arXiv preprint arXiv:2401.16765, 2024.
W. Zhou, X. Wang, L. Xiong, H. Xia, Y. Gu, M. Chai, F. Zhu,C. Huang, S. Dou, Z. Xi et al., “Easyjailbreak: A unified framework forjailbreaking large language models,” arXiv preprint arXiv:2403.12171,2024.
X. Zou, Y. Chen, and K. Li, “Is the system message really important tojailbreaks in large language models?” arXiv preprint arXiv:2402.14857,2024.
Z. Xiao, Y. Yang, G. Chen, and Y. Chen, “Tastle: Distract large languagemodels for automatic jailbreak attack,” in EMNLP, 2024.
B. Li, H. Xing, C. Huang, J. Qian, H. Xiao, L. Feng, and C. Tian,“Structuralsleight: Automated jailbreak attacks on large languagemodels utilizing uncommon text-encoded structure,” arXiv preprintarXiv:2406.08754, 2024.
H. Lv, X. Wang, Y. Zhang, C. Huang, S. Dou, J. Ye, T. Gui,Q. Zhang, and X. Huang, “Codechameleon: Personalized encryptionframework for jailbreaking large language models,” arXiv preprintarXiv:2402.16717, 2024.
Z. Chang, M. Li, Y. Liu, J. Wang, Q. Wang, and Y. Liu, “Play guessinggame with llm: Indirect jailbreak attack with implicit clues,” in ACL,2024.
X. Liu, N. Xu, M. Chen, and C. Xiao, “AutoDAN: Generating stealthyjailbreak prompts on aligned large language models,” in ICLR, 2024.
J. Yu, X. Lin, Z. Yu, and X. Xing, “Gptfuzzer: Red teaming largelanguage models with auto-generated jailbreak prompts,” arXiv preprintarXiv:2309.10253, 2023.
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E.Wong,“Jailbreaking black box large language models in twenty queries,” inNeurIPS Workshop, 2023.
G. Deng, Y. Liu, Y. Li, K. Wang, Y. Zhang, Z. Li, H. Wang, T. Zhang,and Y. Liu, “Masterkey: Automated jailbreaking of large languagemodel chatbots,” in NDSS, 2024.
J. Yu, H. Luo, J. Yao-Chieh, W. Guo, H. Liu, and X. Xing, “Enhancingjailbreak attack against large language models through silent tokens,”arXiv preprint arXiv:2405.20653, 2024.
D. Yao, J. Zhang, I. G. Harris, and M. Carlsson, “Fuzzllm: A noveland universal fuzzing framework for proactively discovering jailbreakvulnerabilities in large language models,” in ICASSP, 2024.
J. Zhang, Z. Wang, R. Wang, X. Ma, and Y.-G. Jiang, “Enja: Ensemblejailbreak on large language models,” arXiv preprint arXiv:2408.03603,2024.
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese,N. McAleese, and G. Irving, “Red teaming language models withlanguage models,” in EMNLP, 2022.
Z.-W. Hong, I. Shenfeld, T.-H. Wang, Y.-S. Chuang, A. Pareja, J. Glass,A. Srivastava, and P. Agrawal, “Curiosity-driven red-teaming for largelanguage models,” in ICLR, 2024.
X. Shen, Z. Chen, M. Backes, Y. Shen, and Y. Zhang, ““do anythingnow”: Characterizing and evaluating in-the-wild jailbreak prompts onlarge language models,” in ACM CCS, 2024.
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson,“Universal and transferable adversarial attacks on aligned languagemodels,” arXiv preprint arXiv:2307.15043, 2023.
X. Jia, T. Pang, C. Du, Y. Huang, J. Gu, Y. Liu, X. Cao, and M. Lin,“Improved techniques for optimization-based jailbreaking on largelanguage models,” arXiv preprint arXiv:2405.21018, 2024.
X. Zheng, T. Pang, C. Du, Q. Liu, J. Jiang, and M. Lin, “Improved fewshotjailbreaking can circumvent aligned language models and theirdefenses,” in arXiv preprint arXiv:2406.01288, 2024.
X. Zhao, X. Yang, T. Pang, C. Du, L. Li, Y.-X. Wang, and W. Y. Wang,“Weak-to-strong jailbreaking on large language models,” arXiv preprintarXiv:2401.17256, 2024.
W. Jiang, Z. Wang, J. Zhai, S. Ma, Z. Zhao, and C. Shen, “Unlockingadversarial suffix optimization without affirmative phrases:Efficient black-box jailbreaking via llm as optimizer,” arXiv preprintarXiv:2408.11313, 2024.
A. Robey, E. Wong, H. Hassani, and G. J. Pappas, “Smoothllm:Defending large language models against jailbreaking attacks,” arXivpreprint arXiv:2310.03684, 2023.
J. Ji, B. Hou, A. Robey, G. J. Pappas, H. Hassani, Y. Zhang, E. Wong,and S. Chang, “Defending large language models against jailbreakattacks via semantic smoothing,” arXiv preprint arXiv:2402.16192,2024.
X. Wang, D. Wu, Z. Ji, Z. Li, P. Ma, S. Wang, Y. Li, Y. Liu,N. Liu, and J. Rahmel, “Selfdefend: Llms can defend themselves againstjailbreaking in a practical manner,” arXiv preprint arXiv:2406.05498,2024.
Z. Liu, Z.Wang, L. Xu, J. Wang, L. Song, T. Wang, C. Chen, W. Cheng,and J. Bian, “Protecting your llms with information bottleneck,” inNeurIPS, 2024.
Y. Wang, Z. Shi, A. Bai, and C.-J. Hsieh, “Defending llms againstjailbreaking attacks via backtranslation,” in ACL, 2024.
J. Kim, A. Derakhshan, and I. G. Harris, “Robust safety classifieragainst jailbreaking attacks: Adversarial prompt shield,” in WOAH,2024.
C. Xiong, X. Qi, P.-Y. Chen, and T.-Y. Ho, “Defensive prompt patch: Arobust and interpretable defense of llms against jailbreak attacks,” arXivpreprint arXiv:2405.20099, 2024.
X. Hu, P.-Y. Chen, and T.-Y. Ho, “Gradient cuff: Detecting jailbreakattacks on large language models by exploring refusal loss landscapes,”in NeurIPS, 2024.
B. Chen, A. Paliwal, and Q. Yan, “Jailbreaker in jail: Moving targetdefense for large language models,” in MTD, 2023.
Z. Zhang, Q. Zhang, and J. Foerster, “Parden, can you repeatthat? defending against jailbreaks via repetition,” arXiv preprintarXiv:2405.07932, 2024.
L. Lu, H. Yan, Z. Yuan, J. Shi, W. Wei, P.-Y. Chen, and P. Zhou,“Autojailbreak: Exploring jailbreak attacks and defenses through adependency lens,” arXiv preprint arXiv:2406.03805, 2024.
Y. Du, S. Zhao, D. Zhao, M. Ma, Y. Chen, L. Huo, Q. Yang, D. Xu,and B. Qin, “MoGU: A framework for enhancing safety of LLMs whilepreserving their usability,” in NeurIPS, 2024.
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques forlanguage models,” in NeurIPS Workshop, 2022.
Y. Liu, G. Deng, Y. Li, K. Wang, Z. Wang, X. Wang, T. Zhang,Y. Liu, H. Wang, Y. Zheng et al., “Prompt injection attack against llmintegratedapplications,” arXiv preprint arXiv:2306.05499, 2023.
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, andM. Fritz, “Not what you’ve signed up for: Compromising real-worldllm-integrated applications with indirect prompt injection,” in AISec,2023.
B. Deng, W. Wang, F. Feng, Y. Deng, Q. Wang, and X. He, “Attackprompt generation for red teaming and defending large language models,”in EMNLP, 2023.
Y. Liu, Y. Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing andbenchmarking prompt injection attacks and defenses,” in USENIXSecurity, 2024, pp. 1831–1847.
R. Ye, X. Pang, J. Chai, J. Chen, Z. Yin, Z. Xiang, X. Dong,J. Shao, and S. Chen, “Are we there yet? revealing the risks ofutilizing large language models in scholarly peer review,” arXiv preprintarXiv:2412.01708, 2024.
X. Liu, Z. Yu, Y. Zhang, N. Zhang, and C. Xiao, “Automatic anduniversal prompt injection attacks against large language models,” arXivpreprint arXiv:2403.04957, 2024.
C. Zhang, M. Jin, Q. Yu, C. Liu, H. Xue, and X. Jin, “Goal-guidedgenerative prompt injection attack on large language models,” arXivpreprint arXiv:2404.07234, 2024.
B. Hui, H. Yuan, N. Gong, P. Burlina, and Y. Cao, “Pleak: Promptleaking attacks against large language model applications,” in ACMSIGSAC CCS, 2024.
J. Shi, Z. Yuan, Y. Liu, Y. Huang, P. Zhou, L. Sun, and N. Z. Gong,“Optimization-based prompt injection attack to llm-as-a-judge,” in ACMSIGSAC CCS, 2024.
Z. Shao, H. Liu, J. Mu, and N. Z. Gong, “Making llms vulnerableto prompt injection via poisoning alignment,” arXiv preprintarXiv:2410.14827, 2024.
S. Chen, J. Piet, C. Sitawarin, and D.Wagner, “Struq: Defending againstprompt injection with structured queries,” USENIX Security, 2025.
R. K. Sharma, V. Gupta, and D. Grossman, “Spml: A dsl fordefending language models against prompt attacks,” arXiv preprintarXiv:2402.11755, 2024.
J. Piet, M. Alrashed, C. Sitawarin, S. Chen, Z. Wei, E. Sun, B. Alomair,and D. Wagner, “Jatmo: Prompt injection defense by task-specificfinetuning,” arXiv preprint arXiv:2312.17673, 2023.
J. Yi, Y. Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, and F. Wu,“Benchmarking and defending against indirect prompt injection attackson large language models,” arXiv preprint arXiv:2312.14197, 2023.
S. Chen, A. Zharmagambetov, S. Mahloujifar, K. Chaudhuri, D. Wagner,and C. Guo, “Secalign: Defending against prompt injection withpreference optimization,” arXiv preprint arXiv:2410.05451v2, 2025.
X. Cai, H. Xu, S. Xu, Y. Zhang et al., “Badprompt: Backdoor attackson continuous prompts,” NeurIPS, 2022.
J. Yan, V. Gupta, and X. Ren, “Bite: Textual backdoor attacks withiterative trigger injection,” in ACL, 2023.
H. Yao, J. Lou, and Z. Qin, “Poisonprompt: Backdoor attack on promptbasedlarge language models,” in ICASSP, 2024.
S. Zhao, J. Wen, L. A. Tuan, J. Zhao, and J. Fu, “Prompt as triggers forbackdoor attack: Examining the vulnerability in language models,” inEMNLP, 2023.
J. Xu, M. D. Ma, F. Wang, C. Xiao, and M. Chen, “Instructionsas backdoors: Backdoor vulnerabilities of instruction tuning for largelanguage models,” in NAACL, 2024.
N. Kandpal, M. Jagielski, F. Tramer, and N. Carlini, “Backdoor attacksfor in-context learning with language models,” in ICML Workshop,2023.
Z. Xiang, F. Jiang, Z. Xiong, B. Ramasubramanian, R. Poovendran,and B. Li, “Badchain: Backdoor chain-of-thought prompting for largelanguage models,” in NeurIPS Workshop, 2024.
S. Zhao, M. Jia, L. A. Tuan, F. Pan, and J. Wen, “Universal vulnerabilitiesin large language models: Backdoor attacks for in-context learning,”in EMNLP, 2024.
Y. Qiang, X. Zhou, S. Z. Zade, M. A. Roshani, D. Zytko, and D. Zhu,“Learning to poison large language models during instruction tuning,”arXiv preprint arXiv:2402.13459, 2024.
P. Pathmanathan, S. Chakraborty, X. Liu, Y. Liang, and F. Huang, “Ispoisoning a real threat to llm alignment? maybe more so than youthink,” in ICML Workshop, 2024.
E. Hubinger, C. Denison, J. Mu, M. Lambert, M. Tong, M. MacDiarmid,T. Lanham, D. M. Ziegler, T. Maxwell, N. Cheng et al., “Sleeperagents: Training deceptive llms that persist through safety training,”arXiv preprint arXiv:2401.05566, 2024.
P. He, H. Xu, Y. Xing, H. Liu, M. Yamada, and J. Tang, “Data poisoningfor in-context learning,” arXiv preprint arXiv:2402.02160, 2024.
Q. Zhang, B. Zeng, C. Zhou, G. Go, H. Shi, and Y. Jiang, “Humanimperceptibleretrieval poisoning attacks in llm-powered applications,”arXiv preprint arXiv:2404.17196, 2024.
S. YAN, S. WANG, Y. DUAN, H. HONG, K. LEE, D. KIM, andY. HONG, “An llm-assisted easy-to-trigger poisoning attack on code completion models: Injecting disguised vulnerabilities against strongdetection,” in USENIX Security, 2024.
H. Huang, Z. Zhao, M. Backes, Y. Shen, and Y. Zhang, “Compositebackdoor attacks against large language models,” in NAACL, 2024.
N. Gu, P. Fu, X. Liu, Z. Liu, Z. Lin, and W. Wang, “A gradient controlmethod for backdoor attacks on parameter-efficient tuning,” in ACL,2023.
J. Xue, M. Zheng, T. Hua, Y. Shen, Y. Liu, L. Bölöni, and Q. Lou,“Trojllm: A black-box trojan prompt attack on large language models,”NeurIPS, 2024.
J. Yan, V. Yadav, S. Li, L. Chen, Z. Tang, H. Wang, V. Srinivasan,X. Ren, and H. Jin, “Backdooring instruction-tuned large languagemodels with virtual prompt injection,” in NAACL, 2024.
Q. Zeng, M. Jin, Q. Yu, Z. Wang, W. Hua, Z. Zhou, G. Sun, Y. Meng,S. Ma, Q. Wang et al., “Uncertainty is fragile: Manipulating uncertaintyin large language models,” arXiv preprint arXiv:2407.11282, 2024.
Y. Li, T. Li, K. Chen, J. Zhang, S. Liu, W. Wang, T. Zhang, and Y. Liu,“Badedit: Backdooring large language models by model editing,” inICLR, 2024.
X. He, J. Wang, B. Rubinstein, and T. Cohn, “Imbert: Making bertimmune to insertion-based backdoor attacks,” in TrustNLP, 2023.
J. Li, Z. Wu, W. Ping, C. Xiao, and V. Vydiswaran, “Defending againstinsertion-based textual backdoor attacks via attribution,” in ACL, 2023.
X. Sun, X. Li, Y. Meng, X. Ao, L. Lyu, J. Li, and T. Zhang, “Defendingagainst backdoor attacks in natural language generation,” in AAAI, 2023.
L. Yan, Z. Zhang, G. Tao, K. Zhang, X. Chen, G. Shen, and X. Zhang,“Parafuzz: An interpretability-driven technique for detecting poisonedsamples in nlp,” NeurIPS, 2024.
Z. Xi, T. Du, C. Li, R. Pang, S. Ji, J. Chen, F. Ma, and T. Wang,“Defending pre-trained language models as few-shot learners againstbackdoor attacks,” NeurIPS, 2024.
M. Lamparth and A. Reuel, “Analyzing and editing inner mechanismsof backdoored language models,” in ACM FAccT, 2024.
H. Li, Y. Chen, Z. Zheng, Q. Hu, C. Chan, H. Liu, and Y. Song, “Backdoorremoval for generative large language models,” arXiv preprintarXiv:2405.07667, 2024.
Y. Zeng, W. Sun, T. N. Huynh, D. Song, B. Li, and R. Jia,“Beear: Embedding-based adversarial removal of safety backdoors ininstruction-tuned language models,” in EMNLP, 2024.
N. M. Min, L. H. Pham, Y. Li, and J. Sun, “Crow: Eliminatingbackdoors from large language models via internal consistency regularization,”arXiv preprint arXiv:2411.12768, 2024.
R. R. Tang, J. Yuan, Y. Li, Z. Liu, R. Chen, and X. Hu, “Setting thetrap: Capturing and defeating backdoors in pretrained language modelsthrough honeypots,” NeurIPS, 2023.
Z. Liu, B. Shen, Z. Lin, F. Wang, and W. Wang, “Maximum entropyloss, the silver bullet targeting backdoor attacks in pre-trained languagemodels,” in ACL, 2023.
Z. Wang, Z. Wang, M. Jin, M. Du, J. Zhai, and S. Ma, “Data-centricnlp backdoor defense from the lens of memorization,” arXiv preprintarXiv:2409.14200, 2024.
T. Tong, J. Xu, Q. Liu, and M. Chen, “Securing multi-turn conversationallanguage models against distributed backdoor triggers,” arXivpreprint arXiv:2407.04151, 2024.
Y. Li, Z. Xu, F. Jiang, L. Niu, D. Sahabandu, B. Ramasubramanian, andR. Poovendran, “Cleangen: Mitigating backdoor attacks for generationtasks in large language models,” in EMNLP, 2024.
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei,“Deep reinforcement learning from human preferences,” NeurIPS,2017.
D. M. Ziegler, N. Stiennon, J.Wu, T. B. Brown, A. Radford, D. Amodei,P. Christiano, and G. Irving, “Fine-tuning language models from humanpreferences,” arXiv preprint arXiv:1909.08593, 2019.
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin,C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training languagemodels to follow instructions with human feedback,” NeurIPS, 2022.
J. Dai, X. Pan, R. Sun, J. Ji, X. Xu, M. Liu, Y.Wang, and Y. Yang, “Saferlhf: Safe reinforcement learning from human feedback,” in ICLR, 2024.
G. An, J. Lee, X. Zuo, N. Kosaka, K.-M. Kim, and H. O. Song, “Directpreference-based policy optimization without reward modeling,”NeurIPS, 2023.
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, andC. Finn, “Direct preference optimization: Your language model issecretly a reward model,” NeurIPS, 2024.
Z. Zhou, J. Liu, C. Yang, J. Shao, Y. Liu, X. Yue, W. Ouyang,and Y. Qiao, “Beyond one-preference-for-all: Multi-objective directpreference optimization,” in ACL, 2024.
K. Ethayarajh,W. Xu, N. Muennighoff, D. Jurafsky, and D. Kiela, “Kto:Model alignment as prospect theoretic optimization,” arXiv preprintarXiv:2402.01306, 2024.
C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu,L. Yu et al., “Lima: Less is more for alignment,” NeurIPS, 2024.
Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones,A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon et al., “Constitutionalai: Harmlessness from ai feedback,” arXiv preprint arXiv:2212.08073,2022.
Z. Sun, Y. Shen, Q. Zhou, H. Zhang, Z. Chen, D. Cox, Y. Yang,and C. Gan, “Principle-driven self-alignment of language models fromscratch with minimal human supervision,” NeurIPS, 2024.
K. Yang, D. Klein, A. Celikyilmaz, N. Peng, and Y. Tian, “RLCD:Reinforcement learning from contrastive distillation for LM alignment,”in ICLR, 2024.
R. Liu, R. Yang, C. Jia, G. Zhang, D. Zhou, A. M. Dai, D. Yang, andS. Vosoughi, “Training socially aligned language models on simulatedsocial interactions,” in ICLR, 2024.
X. Pang, S. Tang, R. Ye, Y. Xiong, B. Zhang, Y. Wang, and S. Chen,“Self-alignment of large language models via monopolylogue-basedsocial scene simulation,” arXiv preprint arXiv:2402.05699, 2024.
S. Chen, C. Liu, M. Haque, Z. Song, and W. Yang, “Nmtsloth: understandingand testing efficiency degradation of neural machine translationsystems,” in ESEC/FSE, 2022.
Y. Chen, S. Chen, Z. Li, W. Yang, C. Liu, R. Tan, and H. Li, “Dynamictransformers provide a false sense of efficiency,” in ACL, 2023.
X. Feng, X. Han, S. Chen, and W. Yang, “Llmeffichecker: Understandingand testing efficiency degradation of large language models,” ACMTransactions on Software Engineering and Methodology, vol. 33, p. 38,2024.
X. Gao, Y. Chen, X. Yue, Y. Tsao, and N. F. Chen, “Ttslow: Slow downtext-to-speech with efficiency robustness evaluations,” arXiv preprintarXiv:2407.01927, 2024.
S. Zhang, M. Zhang, X. Pan, and M. Yang, “No-skim: Towardsefficiency robustness evaluation on skimming-based language models,”arXiv preprint arXiv:2312.09494, 2023.
K. Gao, T. Pang, C. Du, Y. Yang, S.-T. Xia, and M. Lin, “Denial-ofservicepoisoning attacks against large language models,” arXiv preprintarXiv:2410.10760, 2024.
Y. Jiang, C. Chan, M. Chen, and W. Wang, “Lion: Adversarial distillationof proprietary large language models,” in EMNLP, 2023.
Z. Li, C. Wang, P. Ma, C. Liu, S. Wang, D. Wu, C. Gao, and Y. Liu,“On extracting specialized code abilities from large language models:A feasibility study,” in ICSE, 2024.
Z. Liang, Q. Ye, Y. Wang, S. Zhang, Y. Xiao, R. Li, J. Xu, and H. Hu,“Alignment-aware model extraction attacks on large language models,”arXiv preprint arXiv:2409.02718, 2024.
N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, “The secretsharer: Evaluating and testing unintended memorization in neural networks,”in USENIX Security, 2019.
N. Carlini, F. Tramer, E.Wallace, M. Jagielski, A. Herbert-Voss, K. Lee,A. Roberts, T. Brown, D. Song, U. Erlingsson et al., “Extracting trainingdata from large language models,” in USENIX Security, 2021.
M. Nasr, N. Carlini, J. Hayase, M. Jagielski, A. F. Cooper, D. Ippolito,C. A. Choquette-Choo, E. Wallace, F. Tramer, and K. Lee, “Scalableextraction of training data from (production) language models,” arXivpreprint arXiv:2311.17035, 2023.
Z. Xu, F. Jiang, L. Niu, Y. Deng, R. Poovendran, Y. Choi, and B. Y. Lin,“Magpie: Alignment data synthesis from scratch by prompting alignedllms with nothing,” arXiv preprint arXiv:2406.08464, 2024.
A. Al-Kaswan, M. Izadi, and A. Van Deursen, “Traces of memorisationin large language models for code,” in ICSE, 2024.
Y. Bai, G. Pei, J. Gu, Y. Yang, and X. Ma, “Special characters attack:Toward scalable training data extraction from large language models,”arXiv preprint arXiv:2405.05990, 2024.
A. M. Kassem, O. Mahmoud, N. Mireshghallah, H. Kim, Y. Tsvetkov,Y. Choi, S. Saad, and S. Rana, “Alpaca against vicuna: Using llms touncover memorization of llms,” arXiv preprint arXiv:2403.04801, 2024.
Z. Qi, H. Zhang, E. Xing, S. Kakade, and H. Lakkaraju, “Follow myinstruction and spill the beans: Scalable data extraction from retrievalaugmentedgeneration systems,” arXiv preprint arXiv:2402.17840,2024.
Y. More, P. Ganesh, and G. Farnadi, “Towards more realistic extractionattacks: An adversarial perspective,” arXiv preprint arXiv:2407.02596,2024.
W. Yu, T. Pang, Q. Liu, C. Du, B. Kang, Y. Huang, M. Lin, and S. Yan,“Bag of tricks for training data extraction from language models,” inICML, 2023.
S. Duan, M. Khona, A. Iyer, R. Schaeffer, and I. R. Fiete, “Uncoveringlatent memories: Assessing data leakage and memorization patterns inlarge language models,” in ICML Workshop, 2024.
J. Zhang, Q. Yi, and J. Sang, “Towards adversarial attack on visionlanguagepre-training models,” in ACM MM, 2022.
Z. Zhou, S. Hu, M. Li, H. Zhang, Y. Zhang, and H. Jin, “Advclip:Downstream-agnostic adversarial examples in multimodal contrastivelearning,” in ACM MM, 2023.
D. A. Noever and S. E. M. Noever, “Reading isn’t believing: Adversarialattacks on multi-modal neurons,” arXiv preprint arXiv:2103.10480,2021.
D. Lu, Z. Wang, T. Wang, W. Guan, H. Gao, and F. Zheng, “Set-levelguidance attack: Boosting adversarial transferability of vision-languagepre-training models,” in ICCV, 2023.
B. He, X. Jia, S. Liang, T. Lou, Y. Liu, and X. Cao, “Sa-attack:Improving adversarial transferability of vision-language pre-trainingmodels via self-augmentation,” arXiv preprint arXiv:2312.04913, 2023.
Y. Wang, W. Hu, Y. Dong, H. Zhang, H. Su, and R. Hong, “Exploringtransferability of multimodal adversarial samples for visionlanguagepre-training models with contrastive learning,” arXiv preprintarXiv:2308.12636, 2023.
H. Wang, K. Dong, Z. Zhu, H. Qin, A. Liu, X. Fang, J. Wang, andX. Liu, “Transferable multimodal attack on vision-language pre-trainingmodels,” in IEEE S&P, 2024.
Z. Yin, M. Ye, T. Zhang, T. Du, J. Zhu, H. Liu, J. Chen, T. Wang, andF. Ma, “Vlattack: Multimodal adversarial attacks on vision-languagetasks via pre-trained models,” in NeurIPS, 2023.
A. Hu, J. Gu, F. Pinto, K. Kamnitsas, and P. Torr, “As firm astheir foundations: Can open-sourced foundation models be used tocreate adversarial examples for downstream tasks?” arXiv preprintarXiv:2403.12693, 2024.
H. Fang, J. Kong, W. Yu, B. Chen, J. Li, S. Xia, and K. Xu, “Oneperturbation is enough: On generating universal adversarial perturbationsagainst vision-language pre-training models,” arXiv preprintarXiv:2406.05491, 2024.
P.-F. Zhang, Z. Huang, and G. Bai, “Universal adversarial perturbationsfor vision-language pre-trained models,” in SIGIR, 2024.
H. Azuma and Y. Matsui, “Defense-prefix for preventing typographicattacks on clip,” in ICCV, 2023.
J. Zhang, X. Ma, X. Wang, L. Qiu, J. Wang, Y.-G. Jiang, and J. Sang,“Adversarial prompt tuning for vision-language models,” in ECCV,2024.
L. Li, H. Guan, J. Qiu, and M. Spratling, “One prompt word is enoughto boost adversarial robustness for pre-trained vision-language models,”in CVPR, 2024.
H. Fan, Z. Ma, Y. Li, R. Tian, Y. Chen, and C. Gao, “Mixprompt: Enhancinggeneralizability and adversarial robustness for vision-languagemodels via prompt fusion,” in ICIC, 2024.
N. Hussein, F. Shamshad, M. Naseer, and K. Nandakumar,“Promptsmooth: Certifying robustness of medical vision-language modelsvia prompt learning,” in MICCAI, 2024.
Y. Zhou, X. Xia, Z. Lin, B. Han, and T. Liu, “Few-shot adversarialprompt learning on vision-language models,” in NeurIPS, 2024.
L. Luo, X. Wang, B. Zi, S. Zhao, and X. Ma, “Adversarial prompt distillationfor vision-language models,” arXiv preprint arXiv:2411.15244,2024.
X. Wang, K. Chen, J. Zhang, J. Chen, and X. Ma, “Tapt: Testtimeadversarial prompt tuning for robust inference in vision-languagemodels,” arXiv preprint arXiv:2411.13136, 2024.
C. Mao, S. Geng, J. Yang, X. Wang, and C. Vondrick, “Understandingzero-shot adversarial robustness for large-scale models,” in ICLR, 2023.
S. Wang, J. Zhang, Z. Yuan, and S. Shan, “Pre-trained model guidedfine-tuning for zero-shot adversarial robustness,” in CVPR, 2024.
W. Zhou, S. Bai, Q. Zhao, and B. Chen, “Revisiting the adversarialrobustness of vision language models: a multimodal perspective,” arXivpreprint arXiv:2404.19287, 2024.
C. Schlarmann, N. D. Singh, F. Croce, and M. Hein, “Robust CLIP:Unsupervised adversarial fine-tuning of vision embeddings for robustlarge vision-language models,” in ICML, 2024.
Z. Wang, X. Li, H. Zhu, and C. Xie, “Revisiting adversarial training atscale,” in CVPR, 2024.
Z. Gan, Y.-C. Chen, L. Li, C. Zhu, Y. Cheng, and J. Liu, “Large-scaleadversarial training for vision-and-language representation learning,” inNeurIPS, 2020.
S. Fares, K. Ziu, T. Aremu, N. Durasov, M. Takaˇc, P. Fua, K. Nandakumar,and I. Laptev, “Mirrorcheck: Efficient adversarial defense forvision-language models,” arXiv preprint arXiv:2406.09250, 2024.
X. Wang, K. Chen, X. Ma, Z. Chen, J. Chen, and Y.-G. Jiang,“AdvQDet: Detecting query-based adversarial attacks with adversarialcontrastive prompt tuning,” in ACM MM, 2024.
J. Jia, Y. Liu, and N. Z. Gong, “Badencoder: Backdoor attacks to pretrainedencoders in self-supervised learning,” in IEEE S&P, 2022.
J. Zhang, H. Liu, J. Jia, and N. Z. Gong, “Data poisoning basedbackdoor attacks to contrastive learning,” in CVPR, 2024.
S. Liang, M. Zhu, A. Liu, B. Wu, X. Cao, and E.-C. Chang, “Badclip:Dual-embedding guided backdoor attack on multimodal contrastivelearning,” in CVPR, 2024.
J. Bai, K. Gao, S. Min, S.-T. Xia, Z. Li, and W. Liu, “Badclip: Triggerawareprompt learning for backdoor attacks on clip,” in CVPR, 2024.
Z. Yang, X. He, Z. Li, M. Backes, M. Humbert, P. Berrang, andY. Zhang, “Data poisoning attacks against multimodal encoders,” inICML, 2023.
N. Carlini and A. Terzis, “Poisoning and backdooring contrastivelearning,” in ICLR, 2022.
H. Bansal, N. Singhi, Y. Yang, F. Yin, A. Grover, and K.-W. Chang,“Cleanclip: Mitigating data poisoning attacks in multimodal contrastivelearning,” in ICCV, 2023.
W. Yang, J. Gao, and B. Mirzasoleiman, “Better safe than sorry: PretrainingCLIP against targeted data poisoning and backdoor attacks,” inICML, 2024.
——, “Robust contrastive language-image pretraining against data poisoningand backdoor attacks,” NeurIPS, 2024.
S. Feng, G. Tao, S. Cheng, G. Shen, X. Xu, Y. Liu, K. Zhang, S. Ma,and X. Zhang, “Detecting backdoors in pre-trained encoders,” in CVPR,2023.
I. Sur, K. Sikka, M. Walmer, K. Koneripalli, A. Roy, X. Lin, A. Divakaran,and S. Jha, “Tijo: Trigger inversion with joint optimization fordefending multimodal backdoored models,” in ICCV, 2023.
H. Liu, M. K. Reiter, and N. Z. Gong, “Mudjacking: Patching backdoorvulnerabilities in foundation models,” in USENIX Security, 2024.
L. Zhu, R. Ning, J. Li, C. Xin, and H.Wu, “Seer: Backdoor detection forvision-language models through searching target text and image triggerjointly,” in AAAI, 2024.
H. Huang, S. Erfani, Y. Li, X. Ma, and J. Bailey, “Detecting backdoorsamples in contrastive language image pretraining,” in ICLR, 2025.
C. Schlarmann and M. Hein, “On the adversarial robustness of multimodalfoundation models,” in ICCV, 2023.
X. Cui, A. Aparcedo, Y. K. Jang, and S.-N. Lim, “On the robustness oflarge multimodal models against image adversarial attacks,” in CVPR,2024.
H. Luo, J. Gu, F. Liu, and P. Torr, “An image is worth 1000 lies:Transferability of adversarial images across prompts on vision-languagemodels,” in ICLR, 2024.
K. Gao, Y. Bai, J. Bai, Y. Yang, and S.-T. Xia, “Adversarial robustnessfor visual grounding of multimodal large language models,” in ICLRWorkshop, 2024.
Z. Wang, Z. Han, S. Chen, F. Xue, Z. Ding, X. Xiao, V. Tresp, P. Torr,and J. Gu, “Stop reasoning! when multimodal LLM with chain-ofthoughtreasoning meets adversarial image,” in COLM, 2024.
X. Wang, Z. Ji, P. Ma, Z. Li, and S. Wang, “Instructta: Instructiontunedtargeted attack for large vision-language models,” arXiv preprintarXiv:2312.01886, 2023.
Y. Dong, H. Chen, J. Chen, Z. Fang, X. Yang, Y. Zhang, Y. Tian, H. Su,and J. Zhu, “How robust is google’s bard to adversarial image attacks?”in NeurIPS Workshop, 2023.
Y. Zhao, T. Pang, C. Du, X. Yang, C. Li, N.-M. M. Cheung, and M. Lin,“On evaluating adversarial robustness of large vision-language models,”in NeurIPS, 2024.
Q. Guo, S. Pang, X. Jia, and Q. Guo, “Efficiently adversarial examplesgeneration for visual-language models under targeted transfer scenariosusing diffusion models,” arXiv preprint arXiv:2404.10335, 2024.
J. Zhang, J. Ye, X. Ma, Y. Li, Y. Yang, J. Sang, and D.-Y. Yeung,“Anyattack: Towards large-scale self-supervised generation of targetedadversarial examples for vision-language models,” arXiv preprintarXiv:2410.05346, 2024.
L. Bailey, E. Ong, S. Russell, and S. Emmons, “Image hijacks: Adversarialimages can control generative models at runtime,” arXiv preprintarXiv:2309.00236, 2023.
N. Carlini, M. Nasr, C. A. Choquette-Choo, M. Jagielski, I. Gao,P. W. W. Koh, D. Ippolito, F. Tramer, and L. Schmidt, “Are alignedneural networks adversarially aligned?” NeurIPS, 2024.
X. Qi, K. Huang, A. Panda, P. Henderson, M. Wang, and P. Mittal,“Visual adversarial examples jailbreak aligned large language models,”in AAAI, 2024.
Z. Niu, H. Ren, X. Gao, G. Hua, and R. Jin, “Jailbreaking attack againstmultimodal large language model,” arXiv preprint arXiv:2402.02309,2024.
R. Wang, X. Ma, H. Zhou, C. Ji, G. Ye, and Y.-G. Jiang, “White-boxmultimodal jailbreaks against large vision-language models,” in ACMMM, 2024.
Y. Li, H. Guo, K. Zhou, W. X. Zhao, and J.-R. Wen, “Images areachilles’ heel of alignment: Exploiting visual vulnerabilities for jailbreakingmultimodal large language models,” in ECCV, 2024.
E. Shayegani, Y. Dong, and N. Abu-Ghazaleh, “Jailbreak in pieces:Compositional adversarial attacks on multi-modal language models,” inICLR, 2023.
Y. Gong, D. Ran, J. Liu, C. Wang, T. Cong, A. Wang, S. Duan,and X. Wang, “Figstep: Jailbreaking large vision-language models viatypographic visual prompts,” in AAAI, 2025.
Y. Wu, X. Li, Y. Liu, P. Zhou, and L. Sun, “Jailbreaking gpt-4v via self-adversarial attacks with system prompts,” arXiv preprintarXiv:2311.09127, 2023.
S. Ma, W. Luo, Y. Wang, X. Liu, M. Chen, B. Li, and C. Xiao, “Visualroleplay:Universal jailbreak attack on multimodal large language modelsvia role-playing image characte,” arXiv preprint arXiv:2405.20773,2024.
R. Wang, B. Wang, X. Ma, and Y.-G. Jiang, “Ideator: Jailbreaking vlmsusing vlms,” arXiv preprint arXiv:2411.00827, 2024.
X. Zhang, C. Zhang, T. Li, Y. Huang, X. Jia, X. Xie, Y. Liu, andC. Shen, “A mutation-based method for multi-modal jailbreaking attackdetection,” arXiv preprint arXiv:2312.10766, 2023.
R. K. Sharma, V. Gupta, and D. Grossman, “Defending language modelsagainst image-based prompt attacks via user-provided specifications,” inIEEE SPW, 2024.
Y.Wang, X. Liu, Y. Li, M. Chen, and C. Xiao, “Adashield: Safeguardingmultimodal large language models from structure-based attack viaadaptive shield prompting,” in ECCV, 2024.
R. Pi, T. Han, Y. Xie, R. Pan, Q. Lian, H. Dong, J. Zhang, and T. Zhang,“Mllm-protector: Ensuring mllm’s safety without hurting performance,”in EMNLP, 2024.
Y. Gou, K. Chen, Z. Liu, L. Hong, H. Xu, Z. Li, D.-Y. Yeung, J. T.Kwok, and Y. Zhang, “Eyes closed, safety on: Protecting multimodalllms via image-to-text transformation,” in ECCV, 2024.
P. Wang, D. Zhang, L. Li, C. Tan, X. Wang, K. Ren, B. Jiang,and X. Qiu, “Inferaligner: Inference-time alignment for harmlessnessthrough cross-model guidance,” in EMNLP, 2024.
Y. Zhao, X. Zheng, L. Luo, Y. Li, X. Ma, and Y.-G. Jiang, “Bluesuffix:Reinforced blue teaming for vision-language models against jailbreakattacks,” in ICLR, 2025.
K. Gao, Y. Bai, J. Gu, S.-T. Xia, P. Torr, Z. Li, and W. Liu, “Inducinghigh energy-latency of large vision-language models with verboseimages,” in ICLR, 2024.
E. Bagdasaryan, T.-Y. Hsieh, B. Nassi, and V. Shmatikov, “(ab) usingimages and sounds for indirect instruction injection in multi-modalllms,” arXiv preprint arXiv:2307.10490, 2023.
M. Qraitem, N. Tasnim, K. Saenko, and B. A. Plummer, “Vision-llmscan fool themselves with self-generated typographic attacks,” arXivpreprint arXiv:2402.00626, 2024.
S. Liang, J. Liang, T. Pang, C. Du, A. Liu, E.-C. Chang, and X. Cao,“Revisiting backdoor attacks against large vision-language models,”arXiv preprint arXiv:2406.18844, 2024.
D. Lu, T. Pang, C. Du, Q. Liu, X. Yang, and M. Lin, “Test-timebackdoor attacks on multimodal large language models,” arXiv preprintarXiv:2402.08577, 2024.
Z. Ni, R. Ye, Y. Wei, Z. Xiang, Y. Wang, and S. Chen, “Physical backdoorattack can jeopardize driving with vision-large-language models,”in ICML Workshop, 2024.
X. Tao, S. Zhong, L. Li, Q. Liu, and L. Kong, “Imgtrojan: Jailbreakingvision-language models with one image,” arXiv preprintarXiv:2403.02910, 2024.
Y. Xu, J. Yao, M. Shu, Y. Sun, Z.Wu, N. Yu, T. Goldstein, and F. Huang,“Shadowcast: Stealthy data poisoning attacks against vision-languagemodels,” in NeurIPS, 2024.
C. Du, Y. Li, Z. Qiu, and C. Xu, “Stable diffusion is unstable,” NeurIPS,2024.
Q. Liu, A. Kortylewski, Y. Bai, S. Bai, and A. Yuille, “Discoveringfailure modes of text-guided diffusion models via adversarial search,”in ICLR, 2024.
H. Zhuang, Y. Zhang, and S. Liu, “A pilot study of query-free adversarialattack against stable diffusion,” in CVPR, 2023.
C. Zhang, L. Wang, and A. Liu, “Revealing vulnerabilities in stablediffusion via targeted attacks,” arXiv preprint arXiv:2401.08725, 2024.
L. Struppek, D. Hintersdorf, F. Friedrich, P. Schramowski, K. Kerstinget al., “Exploiting cultural biases via homoglyphs in text-to-imagesynthesis,” Journal of Artificial Intelligence Research, vol. 78, pp. 1017–1068, 2023.
Z. Kou, S. Pei, Y. Tian, and X. Zhang, “Character as pixels: Acontrollable prompt adversarial attacking framework for black-box textguided image generation models.” in IJCAI, 2023.
H. Gao, H. Zhang, Y. Dong, and Z. Deng, “Evaluating the robustnessof text-to-image diffusion models against real-world attacks,” arXivpreprint arXiv:2306.13103, 2023.
G. Daras and A. G. Dimakis, “Discovering the hidden vocabulary ofdalle-2,” arXiv preprint arXiv:2206.00169, 2022.
R. Millière, “Adversarial attacks on image generation with made-upwords,” arXiv preprint arXiv:2208.04135, 2022.
N. Maus, P. Chao, E. Wong, and J. R. Gardner, “Black box adversarialprompting for foundation models,” in NFAML, 2023.
H. Liu, Y. Wu, S. Zhai, B. Yuan, and N. Zhang, “Riatig: Reliableand imperceptible adversarial text-to-image generation with naturalprompts,” in CVPR, 2023.
J. Rando, D. Paleka, D. Lindner, L. Heim, and F. Tramèr, “Red-teamingthe stable diffusion safety filter,” arXiv preprint arXiv:2210.04610,2022.
Y. Yang, R. Gao, X. Wang, T.-Y. Ho, N. Xu, and Q. Xu, “Mmadiffusion:Multimodal attack on diffusion models,” in CVPR, 2024.
Z.-Y. Chin, C.-M. Jiang, C.-C. Huang, P.-Y. Chen, and W.-C. Chiu,“Prompting4debugging: Red-teaming text-to-image diffusion models byfinding problematic prompts,” in ICML, 2024.
Y. Zhang, J. Jia, X. Chen, A. Chen, Y. Zhang, J. Liu, K. Ding, andS. Liu, “To generate or not? safety-driven unlearned diffusion modelsare still easy to generate unsafe images... for now,” arXiv preprintarXiv:2310.11868, 2023.
J. Ma, A. Cao, Z. Xiao, J. Zhang, C. Ye, and J. Zhao, “Jailbreakingprompt attack: A controllable adversarial attack against diffusion models,”arXiv preprint arXiv:2404.02928, 2024.
S. Gao, X. Jia, Y. Huang, R. Duan, J. Gu, Y. Liu, and Q. Guo, “Rt-attack:Jailbreaking text-to-image models via random token,” arXiv preprintarXiv:2408.13896, 2024.
Y. Yang, B. Hui, H. Yuan, N. Gong, and Y. Cao, “Sneakyprompt:Jailbreaking text-to-image generative models,” in IEEE S&P, 2024.
Y. Qu, X. Shen, X. He, M. Backes, S. Zannettou, and Y. Zhang, “Unsafediffusion: On the generation of unsafe images and hateful memes fromtext-to-image models,” in CCS, 2023.
Y. Dong, Z. Li, X. Meng, N. Yu, and S. Guo, “Jailbreaking text-to-imagemodels with llm-based agents,” arXiv preprint arXiv:2408.00523, 2024.
Y. Liu, G. Yang, G. Deng, F. Chen, Y. Chen, L. Shi, T. Zhang,and Y. Liu, “Groot: Adversarial testing for generative text-to-imagemodels with tree-based semantic transformation,” arXiv preprintarXiv:2402.12100, 2024.
Y. Deng and H. Chen, “Divide-and-conquer attack: Harnessing thepower of llm to bypass the censorship of text-to-image generationmodel,” arXiv preprint arXiv:2312.07130, 2023.
Z. Ba, J. Zhong, J. Lei, P. Cheng, Q. Wang, Z. Qin, Z. Wang, andK. Ren, “Surrogateprompt: Bypassing the safety filter of text-to-imagemodels via substitution,” in CCS, 2024.
R. Gandikota, J. Materzynska, J. Fiotto-Kaufman, and D. Bau, “Erasingconcepts from diffusion models,” in ICCV, 2023.
M. Lyu, Y. Yang, H. Hong, H. Chen, X. Jin, Y. He, H. Xue, J. Han, andG. Ding, “One-dimensional adapter to rule them all: Concepts diffusionmodels and erasing applications,” in CVPR, 2024.
S. Kim, S. Jung, B. Kim, M. Choi, J. Shin, and J. Lee, “Towardssafe self-distillation of internet-scale text-to-image diffusion models,”in ICML Workshop, 2023.
N. Kumari, B. Zhang, S.-Y. Wang, E. Shechtman, R. Zhang, and J.-Y.Zhu, “Ablating concepts in text-to-image diffusion models,” in ICCV,2023.
S. Hong, J. Lee, and S. S. Woo, “All but one: Surgical concept erasingwith model preservation in text-to-image diffusion models,” in AAAI,2024.
Y. Wu, S. Zhou, M. Yang, L. Wang, W. Zhu, H. Chang, X. Zhou,and X. Yang, “Unlearning concepts in diffusion model via conceptdomain correction and concept preserving gradient,” arXiv preprintarXiv:2405.15304, 2024.
A. Heng and H. Soh, “Selective amnesia: A continual learning approachto forgetting in deep generative models,” NeurIPS, 2024.
C.-P. Huang, K.-P. Chang, C.-T. Tsai, Y.-H. Lai, and Y.-C. F. Wang,“Receler: Reliable concept erasing of text-to-image diffusion modelsvia lightweight erasers,” in ECCV, 2024.
C. Kim, K. Min, and Y. Yang, “Race: Robust adversarial concept erasurefor secure text-to-image diffusion model,” in ECCV, 2024.
Y. Zhang, X. Chen, J. Jia, Y. Zhang, C. Fan, J. Liu, M. Hong, K. Ding,and S. Liu, “Defensive unlearning with adversarial training for robustconcept erasure in diffusion models,” in NeurIPS, 2024.
Z. Ni, L. Wei, J. Li, S. Tang, Y. Zhuang, and Q. Tian, “Degenerationtuning:Using scrambled grid shield unwanted concepts from stablediffusion,” in ACM MM, 2023.
G. Zhang, K. Wang, X. Xu, Z. Wang, and H. Shi, “Forget-me-not:Learning to forget in text-to-image diffusion models,” in CVPR, 2024.
Z. Liu, K. Chen, Y. Zhang, J. Han, L. Hong, H. Xu, Z. Li, D.-Y. Yeung,and J. Kwok, “Implicit concept removal of diffusion models,” arXivpreprint arXiv:2310.05873, 2024.
M. Zhao, L. Zhang, T. Zheng, Y. Kong, and B. Yin, “Separablemulti-concept erasure from diffusion models,” arXiv preprintarXiv:2402.05947, 2024.
S. Lu, Z.Wang, L. Li, Y. Liu, and A.W.-K. Kong, “Mace: Mass concepterasure in diffusion models,” in CVPR, 2024.
R. Gandikota, H. Orgad, Y. Belinkov, J. Materzy´nska, and D. Bau,“Unified concept editing in diffusion models,” in WACV, 2024.
H. Orgad, B. Kawar, and Y. Belinkov, “Editing implicit assumptions intext-to-image diffusion models,” in ICCV, 2023.
C. Gong, K. Chen, Z. Wei, J. Chen, and Y.-G. Jiang, “Reliable andefficient concept erasure of text-to-image diffusion models,” in ECCV,2024.
Y. Liu, J. An, W. Zhang, M. Li, D. Wu, J. Gu, Z. Lin, and W. Wang,“Realera: Semantic-level concept erasure via neighbor-concept mining,”arXiv preprint arXiv:2410.09140, 2024.
R. Chavhan, D. Li, and T. Hospedales, “Conceptprune: Concept editingin diffusion models via skilled neuron pruning,” in NeurIPS, 2024.
T. Yang, Z. Li, J. Cao, and C. Xu, “Pruning for robust concept erasingin diffusion models,” in Neurips Workshop, 2024.
T. Han, W. Sun, Y. Hu, C. Fang, Y. Zhang, S. Ma, T. Zheng, Z. Chen,and Z. Wang, “Continuous concepts removal in text-to-image diffusionmodels,” arXiv preprint arXiv:2412.00580, 2024.
P. Schramowski, M. Brack, B. Deiseroth, and K. Kersting, “Safe latentdiffusion: Mitigating inappropriate degeneration in diffusion models,”in CVPR, 2023.
Y. Cai, S. Yin, Y. Wei, C. Xu, W. Mao, F. Juefei-Xu, S. Chen, andY. Wang, “Ethical-lens: Curbing malicious usages of open-source textto-image models,” arXiv preprint arXiv:2404.12104, 2024.
H. Li, C. Shen, P. Torr, V. Tresp, and J. Gu, “Self-discoveringinterpretable diffusion latent directions for responsible text-to-imagegeneration,” in CVPR, 2024.
S.-Y. Chou, P.-Y. Chen, and T.-Y. Ho, “How to backdoor diffusionmodels?” in CVPR, 2023.
——, “Villandiffusion: A unified backdoor attack framework for diffusionmodels,” NeurIPS, 2024.
W. Chen, D. Song, and B. Li, “Trojdiff: Trojan attacks on diffusionmodels with diverse targets,” in CVPR, 2023.
S. Li, J. Ma, and M. Cheng, “Invisible backdoor attacks on diffusionmodels,” arXiv preprint arXiv:2406.00816, 2024.
C. Li, R. Pang, B. Cao, J. Chen, F. Ma, S. Ji, and T. Wang, “Watchthe watcher! backdoor attacks on security-enhancing diffusion models,”arXiv preprint arXiv:2406.09669, 2024.
L. Struppek, D. Hintersdorf, and K. Kersting, “Rickrolling the artist:Injecting backdoors into text encoders for text-to-image synthesis,” inICCV, 2023.
S. Zhai, Y. Dong, Q. Shen, S. Pu, Y. Fang, and H. Su, “Text-to-imagediffusion models can be easily backdoored through multimodal datapoisoning,” in ACM MM, 2023.
Z. Pan, Y. Yao, G. Liu, B. Shen, H. V. Zhao, R. R. Kompella, and S. Liu,“From trojan horses to castle walls: Unveiling bilateral backdoor effectsin diffusion models,” in NeurIPS Workshop, 2024.
J. Vice, N. Akhtar, R. Hartley, and A. Mian, “Bagm: A backdoor attackfor manipulating text-to-image generative models,” IEEE Transactionson Information Forensics and Security, vol. 19, pp. 4865–4880, 2024.
Y. Huang, Q. Guo, and F. Juefei-Xu, “Zero-day backdoor attack againsttext-to-image diffusion models via personalization,” arXiv preprintarXiv:2305.10701, 2023.
Y. Huang, F. Juefei-Xu, Q. Guo, J. Zhang, Y. Wu, M. Hu, T. Li, G. Pu,and Y. Liu, “Personalization as a shortcut for few-shot backdoor attackagainst text-to-image diffusion models,” in AAAI, 2024.
H.Wang, Q. Shen, Y. Tong, Y. Zhang, and K. Kawaguchi, “The strongerthe diffusion model, the easier the backdoor: Data poisoning to inducecopyright breaches without adjusting finetuning pipeline,” in NeurIPSWorkshop, 2024.
A. Naseh, J. Roh, E. Bagdasaryan, and A. Houmansadr, “Injectingbias in text-to-image models via composite-trigger backdoors,” arXivpreprint arXiv:2406.15213, 2024.
Z.Wang, J. Zhang, S. Shan, and X. Chen, “T2ishield: Defending againstbackdoors on text-to-image diffusion models,” in ECCV, 2024.
Z. Guan, M. Hu, S. Li, and A. Vullikanti, “Ufid: A unified frameworkfor input-level backdoor detection on diffusion models,” arXiv preprintarXiv:2404.01101, 2024.
Y. Sui, H. Phan, J. Xiao, T. Zhang, Z. Tang, C. Shi, Y. Wang, Y. Chen,and B. Yuan, “Disdet: Exploring detectability of backdoor attack ondiffusion models,” arXiv preprint arXiv:2402.02739, 2024.
S. An, S.-Y. Chou, K. Zhang, Q. Xu, G. Tao, G. Shen, S. Cheng, S. Ma,P.-Y. Chen, T.-Y. Ho et al., “Elijah: Eliminating backdoors injected indiffusion models via distribution shift,” in AAAI, 2024.
J. Hao, X. Jin, H. Xiaoguang, and C. Tianyou, “Diff-cleanse: Identifyingand mitigating backdoor attacks in diffusion models,” arXiv preprintarXiv:2407.21316, 2024.
Y. Mo, H. Huang, M. Li, A. Li, and Y. Wang, “TERD: A unifiedframework for safeguarding diffusion models against backdoors,” inICML, 2024.
V. T. Truong and L. B. Le, “Purediffusion: Using backdoor tocounter backdoor in generative diffusion models,” arXiv preprintarXiv:2409.13945, 2024.
J. Dubi´nski, A. Kowalczuk, S. Pawlak, P. Rokita, T. Trzci´nski, andP. Morawiecki, “Towards more realistic membership inference attackson large diffusion models,” in WACV, 2024.
Y. Pang, T. Wang, X. Kang, M. Huai, and Y. Zhang, “White-boxmembership inference attacks against diffusion models,” arXiv preprintarXiv:2308.06405, 2023.
T. Matsumoto, T. Miura, and N. Yanai, “Membership inference attacksagainst diffusion models,” in SPW, 2023.
H. Hu and J. Pang, “Loss and likelihood based membership inferenceof diffusion models,” in ICIS, 2023.
J. Duan, F. Kong, S. Wang, X. Shi, and K. Xu, “Are diffusion modelsvulnerable to membership inference attacks?” in ICML, 2023.
S. Tang, Z. S. Wu, S. Aydore, M. Kearns, and A. Roth, “Membershipinference attacks on diffusion models via quantile regression,” arXivpreprint arXiv:2312.05140, 2023.
F. Kong, J. Duan, R. Ma, H. T. Shen, X. Shi, X. Zhu, and K. Xu,“An efficient membership inference attack for the diffusion model byproximal initialization,” in ICLR, 2024.
W. Fu, H. Wang, C. Gao, G. Liu, Y. Li, and T. Jiang, “A probabilisticfluctuation based membership inference attack for generative models,”arXiv preprint arXiv:2308.12143, 2023.
S. Zhai, H. Chen, Y. Dong, J. Li, Q. Shen, Y. Gao, H. Su, andY. Liu, “Membership inference on text-to-image diffusion models viaconditional likelihood discrepancy,” in NeurIPS, 2024.
Q. Li, X. Fu, X. Wang, J. Liu, X. Gao, J. Dai, and J. Han, “Unveilingstructural memorization: Structural membership inference attack fortext-to-image diffusion models,” in ACM MM, 2024.
Y. Wu, N. Yu, Z. Li, M. Backes, and Y. Zhang, “Membership inferenceattacks against text-to-image generation models,” arXiv preprintarXiv:2210.00968, 2022.
Y. Pang and T. Wang, “Black-box membership inference attacks againstfine-tuned diffusion models,” arXiv preprint arXiv:2312.08207, 2023.
J. Li, J. Dong, T. He, and J. Zhang, “Towards black-box membership inferenceattack for diffusion models,” arXiv preprint arXiv:2405.20771,2024.
X. Fu, X. Wang, Q. Li, J. Liu, J. Dai, and J. Han, “Model will tell:Training membership inference for diffusion models,” arXiv preprintarXiv:2403.08487, 2024.
M. Zhang, N. Yu, R. Wen, M. Backes, and Y. Zhang, “Generateddistributions are all you need for membership inference attacks againstgenerative models,” in CVPR, 2024.
N. Carlini, J. Hayes, M. Nasr, M. Jagielski, V. Sehwag, F. Tramer,B. Balle, D. Ippolito, and E. Wallace, “Extracting training data fromdiffusion models,” in USENIX Security, 2023.
R.Webster, “A reproducible extraction of training images from diffusionmodels,” arXiv preprint arXiv:2305.08694, 2023.
Y. Chen, X. Ma, D. Zou, and Y.-G. Jiang, “Towards a theoreticalunderstanding of memorization in diffusion models,” arXiv preprintarXiv:2410.02467, 2024.
X. Wu, J. Zhang, and S. Wu, “Revealing the unseen: Guiding personalizeddiffusion models to expose training data,” arXiv preprintarXiv:2410.03039, 2024.
E. Horwitz, J. Kahana, and Y. Hoshen, “Recovering the pre-fine-tuningweights of generative models,” arXiv preprint arXiv:2402.10208, 2024.
X. Ye, H. Huang, J. An, and Y. Wang, “DUAW: Data-free universaladversarial watermark against stable diffusion customization,” in ICLRWorkshop, 2024.
C. Liang, X. Wu, Y. Hua, J. Zhang, Y. Xue, T. Song, Z. Xue, R. Ma,and H. Guan, “Adversarial example does good: Preventing paintingimitation from diffusion models via adversarial examples,” in ICML,2023.
T. Van Le, H. Phung, T. H. Nguyen, Q. Dao, N. N. Tran, and A. Tran,“Anti-dreambooth: Protecting users from personalized text-to-imagesynthesis,” in ICCV, 2023.
Y. Liu, C. Fan, Y. Dai, X. Chen, P. Zhou, and L. Sun, “Metacloak:Preventing unauthorized subject-driven text-to-image diffusion-basedsynthesis via meta-learning,” in CVPR, 2024.
H. Liu, Z. Sun, and Y. Mu, “Countering personalized text-to-imagegeneration with influence watermarks,” in CVPR, 2024.
F. Wang, Z. Tan, T. Wei, Y. Wu, and Q. Huang, “Simac: A simple anticustomizationmethod for protecting face privacy against text-to-imagesynthesis of diffusion models,” in CVPR, 2024.
X. Zhang, R. Li, J. Yu, Y. Xu, W. Li, and J. Zhang, “Editguard: Versatileimage watermarking for tamper localization and copyright protection,”in CVPR, 2024.
R. Min, S. Li, H. Chen, and M. Cheng, “A watermark-conditioneddiffusion model for ip protection,” in 2024, 2024.
P. Zhu, T. Takahashi, and H. Kataoka, “Watermark-embedded adversarialexamples for copyright protection against diffusion models,” inCVPR, 2024.
Y. Cui, J. Ren, Y. Lin, H. Xu, P. He, Y. Xing,W. Fan, H. Liu, and J. Tang,“Ft-shield: A watermark against unauthorized fine-tuning in text-toimagediffusion models,” arXiv preprint arXiv:2310.02401, 2023.
Y. Cui, J. Ren, H. Xu, P. He, H. Liu, L. Sun, Y. Xing, and J. Tang, “Diffusionshield:A watermark for copyright protection against generativediffusion models,” in NeurIPS Workshop, 2023.
V. Asnani, J. Collomosse, T. Bui, X. Liu, and S. Agarwal, “Promark:Proactive diffusion watermarking for causal attribution,” in CVPR,2024.
Z. Wang, C. Chen, L. Lyu, D. N. Metaxas, and S. Ma, “Diagnosis:Detecting unauthorized data usages in text-to-image diffusion models,”in ICLR, 2023.
J. Zhu, R. Kaplan, J. Johnson, and L. Fei-Fei, “Hidden: Hiding datawith deep networks,” in ECCV, 2018.
P. Fernandez, G. Couairon, H. Jegou, M. Douze, and T. Furon, “Thestable signature: Rooting watermarks in latent diffusion models,” inICCV, 2023.
A. Rezaei, M. Akbari, S. R. Alvar, A. Fatemi, and Y. Zhang, “Lawa:Using latent space for in-generation image watermarking,” in ECCV,2024.
Z. Ma, G. Jia, B. Qi, and B. Zhou, “Safe-sd: Safe and traceable stablediffusion with text prompt trigger for invisible generative watermarking,”in ACM MM, 2024.
Y. Zhao, T. Pang, C. Du, X. Yang, N.-M. Cheung, and M. Lin, “A recipefor watermarking diffusion models,” arXiv preprint arXiv:2303.10137,2023.
Y. Liu, Z. Li, M. Backes, Y. Shen, and Y. Zhang, “Watermarkingdiffusion model,” arXiv preprint arXiv:2305.12502, 2023.
S. Peng, Y. Chen, C. Wang, and X. Jia, “Protecting the intellectualproperty of diffusion models by the watermark diffusion process,” arXivpreprint arXiv:2306.03436, vol. 3, 2023.
W. Feng, W. Zhou, J. He, J. Zhang, T. Wei, G. Li, T. Zhang, W. Zhang,and N. Yu, “Aqualora: Toward white-box protection for customizedstable diffusion models via watermark lora,” in ICML, 2024.
Z. Wang, V. Sehwag, C. Chen, L. Lyu, D. N. Metaxas, and S. Ma, “Howto trace latent generative model generated images without artificialwatermark?” in ICML, 2024.
Y. Wen, J. Kirchenbauer, J. Geiping, and T. Goldstein, “Tree-ringwatermarks: Fingerprints for diffusion images that are invisible androbust,” in NeurIPS, 2023.
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “Injecagent: Benchmarkingindirect prompt injections in tool-integrated large language modelagents,” in ACL, 2024.
B. Zhang, Y. Tan, Y. Shen, A. Salem, M. Backes, S. Zannettou, andY. Zhang, “Breaking agents: Compromising autonomous llm agentsthrough malfunction amplification,” arXiv preprint arXiv:2407.20859,2024.
Y. Wang, D. Xue, S. Zhang, and S. Qian, “Badagent: Inserting andactivating backdoor attacks in llm agents,” in ACL, 2024.
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “Agentpoison: Redteamingllm agents via poisoning memory or knowledge bases,” arXivpreprint arXiv:2407.12784, 2024.
A. Liu, Y. Zhou, X. Liu, T. Zhang, S. Liang, J. Wang, Y. Pu, T. Li,J. Zhang, W. Zhou et al., “Compromising embodied agents withcontextual backdoor attacks,” arXiv preprint arXiv:2408.02882, 2024.
Z. Zhang, Y. Zhang, L. Li, H. Gao, L. Wang, H. Lu, F. Zhao, Y. Qiao,and J. Shao, “Psysafe: A comprehensive framework for psychologicalbasedattack, defense, and evaluation of multi-agent system safety,”arXiv preprint arXiv:2401.11880, 2024.
W. Hua, X. Yang, Z. Li, C. Wei, and Y. Zhang, “Trustagent: Towardssafe and trustworthy llm-based agents through agent constitution,” inACL, 2024.
Y. Zeng, Y. Wu, X. Zhang, H. Wang, and Q. Wu, “Autodefense: MultiagentLLM defense against jailbreak attacks,” in Neurips Workshop,2024.
Z. Xiang, L. Zheng, Y. Li, J. Hong, Q. Li, H. Xie, J. Zhang,Z. Xiong, C. Xie, C. Yang et al., “Guardagent: Safeguard llm agentsby a guard agent via knowledge-enabled reasoning,” arXiv preprintarXiv:2406.09187, 2024.
T. Yuan, Z. He, L. Dong, Y. Wang, R. Zhao, T. Xia, L. Xu, B. Zhou,F. Li, Z. Zhang et al., “R-judge: Benchmarking safety risk awarenessfor llm agents,” in EMNLP, 2024.
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer,and F. Tramer, “Agentdojo: A dynamic environment to evaluate promptinjection attacks and defenses for LLM agents,” in NeurIPS, 2024.
S. Yin, X. Pang, Y. Ding, M. Chen, Y. Bi, Y. Xiong,W. Huang, Z. Xiang,J. Shao, and S. Chen, “Safeagentbench: A benchmark for safe taskplanning of embodied llm agents,” arXiv preprint arXiv:2412.13178,2024.
X. Fu, Z. Wang, S. Li, R. K. Gupta, N. Mireshghallah, T. Berg-Kirkpatrick, and E. Fernandes, “Misusing tools in large language modelswith visual adversarial examples,” arXiv preprint arXiv:2310.03185,2023.
Z. Tan, C. Zhao, R. Moraffah, Y. Li, Y. Kong, T. Chen, and H. Liu, “Thewolf within: Covert injection of malice into mllm societies via an mllmoperative,” arXiv preprint arXiv:2402.14859, 2024.
X. Gu, X. Zheng, T. Pang, C. Du, Q. Liu, Y. Wang, J. Jiang, and M. Lin,“Agent smith: A single image can jailbreak one million multimodal llmagents exponentially fast,” in ICML, 2024.
C. H. Wu, J. Y. Koh, R. Salakhutdinov, D. Fried, and A. Raghunathan,“Adversarial attacks on multimodal agents,” arXiv preprintarXiv:2406.12814, 2024.
C. Zhang, X. Xu, J. Wu, Z. Liu, and L. Zhou, “Adversarial attacksof vision tasks in the past 10 years: A survey,” arXiv preprintarXiv:2410.23687, 2024.
V. T. Truong, L. B. Dang, and L. B. Le, “Attacks and defenses forgenerative diffusion models: A comprehensive survey,” arXiv preprintarXiv:2408.03400, 2024.
S. Zhao, M. Jia, Z. Guo, L. Gan, X. Xu, X. Wu, J. Fu, Y. Feng, F. Pan,and L. A. Tuan, “A survey of backdoor attacks and defenses on largelanguage models: Implications for security measures,” arXiv preprintarXiv:2406.06852, 2024.
S. Yi, Y. Liu, Z. Sun, T. Cong, X. He, J. Song, K. Xu, and Q. Li,“Jailbreak attacks and defenses against large language models: Asurvey,” arXiv preprint arXiv:2407.04295, 2024.
H. Jin, L. Hu, X. Li, P. Zhang, C. Chen, J. Zhuang, and H. Wang, “Jailbreakzoo:Survey, landscapes, and horizons in jailbreaking large languageand vision-language models,” arXiv preprint arXiv:2407.01599,2024.
X. Liu, X. Cui, P. Li, Z. Li, H. Huang, S. Xia, M. Zhang, Y. Zou, andR. He, “Jailbreak attacks and defenses against multimodal generativemodels: A survey,” arXiv preprint arXiv:2411.09259, 2024.
D. Liu, M. Yang, X. Qu, P. Zhou, Y. Cheng, and W. Hu, “A surveyof attacks on large vision-language models: Resources, advances, andfuture trends,” arXiv preprint arXiv:2407.07403, 2024.
T. Cui, Y. Wang, C. Fu, Y. Xiao, S. Li, X. Deng, Y. Liu, Q. Zhang,Z. Qiu, P. Li et al., “Risk taxonomy, mitigation, and assessmentbenchmarks of large language model systems,” arXiv preprintarXiv:2401.05778, 2024.
Z. Deng, Y. Guo, C. Han, W. Ma, J. Xiong, S. Wen, and Y. Xiang,“Ai agents under threat: A survey of key security challenges and futurepathways,” arXiv preprint arXiv:2406.02630, 2024.
Y. Gan, Y. Yang, Z. Ma, P. He, R. Zeng, Y. Wang, Q. Li, C. Zhou, S. Li,T. Wang et al., “Navigating the risks: A survey of security, privacy, andethics threats in llm-based agents,” arXiv preprint arXiv:2411.09523,2024.
P. Slattery, A. K. Saeri, E. A. Grundy, J. Graham, M. Noetel, R. Uuk,J. Dao, S. Pour, S. Casper, and N. Thompson, “The ai risk repository:A comprehensive meta-review, database, and taxonomy of risks fromartificial intelligence,” arXiv preprint arXiv:2408.12622, 2024.
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai,T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly,J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words:Transformers for image recognition at scale,” in ICLR, 2021.
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson,T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,”in CVPR, 2023.
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towardsdeep learning models resistant to adversarial attacks,” in ICLR, 2018.
Y. Li, H. Huang, J. Zhang, X. Ma, and Y.-G. Jiang, “Expose beforeyou defend: Unifying and enhancing backdoor defenses via exposedmodels,” arXiv preprint arXiv:2410.19427, 2024.
S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Universaladversarial perturbations,” in CVPR, 2017.
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control totext-to-image diffusion models,” in ICCV, 2023.
H. Huang, X. Ma, S. M. Erfani, J. Bailey, and Y. Wang, “Unlearnableexamples: Making personal data unexploitable,” in ICLR, 2021.
T. Chen, L. Zhu, C. Ding, R. Cao, Y. Wang, Z. Li, L. Sun, P. Mao,and Y. Zang, “Sam fails to segment anything?–sam-adapter: Adaptingsam in underperformed scenes: Camouflage, shadow, medical imagesegmentation, and more,” arXiv preprint arXiv:2304.09148, 2023.
H. Ding, C. Liu, S. He, X. Jiang, P. H. S. Torr, and S. Bai, “MOSE: Anew dataset for video object segmentation in complex scenes,” in ICCV,2023.
H. Ding, C. Liu, S. He, X. Jiang, and C. C. Loy, “MeViS: A large-scalebenchmark for video segmentation with motion expressions,” in ICCV,2023.
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson,U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset forsemantic urban scene understanding,” in CVPR, 2016.
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,P. Dollar, and C. L. Zitnick, “Microsoft coco: Common objects incontext,” in ECCV, 2014.
B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba,“Scene parsing through ade20k dataset,” in CVPR, 2017.
T.-N. Le, T. V. Nguyen, Z. Nie, M.-T. Tran, and A. Sugimoto,“Anabranch network for camouflaged object segmentation,” Computervision and Image Understanding, vol. 184, pp. 45–56, 2019.
OpenAI, “Introducing openai o1,” 2024, accessed: 2025-01-14.
[Online]. Available: https://openai.com/o1/
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma,P. Wang, X. Bi et al., “Deepseek-r1: Incentivizing reasoning capabilityin llms via reinforcement learning,” arXiv preprint arXiv:2501.12948,2025.
N. Carlini, “A llm assisted exploitation of ai-guardian,” arXiv preprintarXiv:2307.15008, 2023.
A. Robey, Z. Ravichandran, V. Kumar, H. Hassani, and G. J. Pappas,“Jailbreaking llm-controlled robots,” arXiv preprint arXiv:2410.13691,2024.
M. Goldblum, D. Tsipras, C. Xie, X. Chen, A. Schwarzschild, D. Song,A. Ma˛dry, B. Li, and T. Goldstein, “Dataset security for machinelearning: Data poisoning, backdoor attacks, and defenses,” IEEE Transactionson Pattern Analysis and Machine Intelligence, vol. 45, pp.1563–1580, 2022.
S. Gehman, S. Gururangan, M. Sap, Y. Choi, and N. A. Smith,“Realtoxicityprompts: Evaluating neural toxic degeneration in languagemodels,” in EMNLP, 2020.
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how modelsmimic human falsehoods,” in ACL, 2022.
B. Wang, C. Xu, S. Wang, Z. Gan, Y. Cheng, J. Gao, A. H. Awadallah,and B. Li, “Adversarial glue: A multi-task benchmark for robustnessevaluation of language models,” in NeurIPS, 2021.
H. Sun, Z. Zhang, J. Deng, J. Cheng, and M. Huang, “Safety assessmentof chinese large language models,” arXiv preprint arXiv:2304.10436,2023.
Y. Wang, H. Li, X. Han, P. Nakov, and T. Baldwin, “Do-not-answer: Adataset for evaluating safeguards in llms,” in EACL, 2024.
G. Xu, J. Liu, M. Yan, H. Xu, J. Si, Z. Zhou, P. Yi, X. Gao,J. Sang, R. Zhang et al., “Cvalues: Measuring the values of chineselarge language models from safety to responsibility,” arXiv preprintarXiv:2307.09705, 2023.
Y. Wang, Y. Teng, K. Huang, C. Lyu, S. Zhang, W. Zhang, X. Ma, Y.-G.Jiang, Y. Qiao, and Y. Wang, “Fake alignment: Are llms really alignedwell?” in NAACL, 2024.
K. Huang, X. Liu, Q. Guo, T. Sun, J. Sun, Y. Wang, Z. Zhou, Y. Wang,Y. Teng, X. Qiu et al., “Flames: Benchmarking value alignment of llmsin chinese,” in NAACL, 2024.
T. Xie, X. Qi, Y. Zeng, Y. Huang, U. M. Sehwag, K. Huang, L. He,B. Wei, D. Li, Y. Sheng et al., “Sorry-bench: Systematically evaluatinglarge language model safety refusal behaviors,” arXiv preprintarXiv:2406.14598, 2024.
Z. Zhang, L. Lei, L. Wu, R. Sun, Y. Huang, C. Long, X. Liu, X. Lei,J. Tang, and M. Huang, “Safetybench: Evaluating the safety of largelanguage models,” in ACL, 2024.
L. Li, B. Dong, R. Wang, X. Hu, W. Zuo, D. Lin, Y. Qiao, and J. Shao,“Salad-bench: A hierarchical and comprehensive safety benchmark forlarge language models,” in ACL, 2024.
Y. Li, H. Huang, Y. Zhao, X. Ma, and J. Sun, “Backdoorllm: A comprehensivebenchmark for backdoor attacks on large language models,”arXiv preprint arXiv:2408.12798, 2024.
W. Luo, S. Ma, X. Liu, X. Guo, and C. Xiao, “Jailbreakv-28k: Abenchmark for assessing the robustness of multimodal large languagemodels against jailbreak attacks,” in COLM, 2024.
A. Souly, Q. Lu, D. Bowen, T. Trinh, E. Hsieh, S. Pandey, P. Abbeel,J. Svegliato, S. Emmons, O. Watkins, and S. Toyer, “A strongREJECTfor empty jailbreaks,” in ICLR Workshop, 2024.
H. Li, X. Han, Z. Zhai, H. Mu, H. Wang, Z. Zhang, Y. Geng, S. Lin,R. Wang, A. Shelmanov et al., “Libra-leaderboard: Towards responsibleai through a balanced leaderboard of safety and capability,” arXivpreprint arXiv:2412.18551, 2024.
Z. Cheng, X. Wu, J. Yu, S. Han, X.-Q. Cai, and X. Xing, “Soft-labelintegration for robust toxicity classification,” in NeurIPS, 2024.
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal,G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferablevisual models from natural language supervision,” in ICML, 2021.
J. Li, R. Selvaraju, A. Gotmare, S. Joty, C. Xiong, and S. C. H. Hoi,“Align before fuse: Vision and language representation learning withmomentum distillation,” in NeurIPS, 2021.
J. Yang, J. Duan, S. Tran, Y. Xu, S. Chanda, L. Chen, B. Zeng,T. Chilimbi, and J. Huang, “Vision-language pre-training with triplecontrastive learning,” in CVPR, 2022.
X. Xu, X. Chen, C. Liu, A. Rohrbach, T. Darrell, and D. Song,“Fooling vision and language models despite localization and attentionmechanism,” in CVPR, 2018.
M. Shah, X. Chen, M. Rohrbach, and D. Parikh, “Cycle-consistency forrobust visual question answering,” in CVPR, 2019.
K. Yang,W.-Y. Lin, M. Barman, F. Condessa, and Z. Kolter, “Defendingmultimodal fusion models against single-source adversaries,” in CVPR,2021.
F. Croce and M. Hein, “Reliable evaluation of adversarial robustnesswith an ensemble of diverse parameter-free attacks,” in ICML, 2020.
C. Zhu, Y. Cheng, Z. Gan, S. Sun, T. Goldstein, and J. Liu, “Freelb:Enhanced adversarial training for natural language understanding,” inICLR, 2020.
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Conditional prompt learningfor vision-language models,” in CVPR, 2022.
——, “Learning to prompt for vision-language models,” InternationalJournal of Computer Vision, vol. 130, pp. 2337–2348, 2022.
M. U. Khattak, H. Rasheed, M. Maaz, S. Khan, and F. S. Khan, “Maple:Multi-modal prompt learning,” in CVPR, 2023.
N. Carlini, M. Jagielski, C. A. Choquette-Choo, D. Paleka, W. Pearce,H. Anderson, A. Terzis, K. Thomas, and F. Tramer, “Poisoning webscaletraining datasets is practical,” in IEEE S&P, 2024.
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma,Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet largescale visual recognition challenge,” International Journal of ComputerVision, vol. 115, pp. 211–252, 2015.
L. Fei-Fei, R. Fergus, and P. Perona, “Learning generative visual modelsfrom few training examples: An incremental bayesian approach testedon 101 object categories,” in CVPRW, 2004.
M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi,“Describing textures in the wild,” in CVPR, 2014.
P. Helber, B. Bischke, A. Dengel, and D. Borth, “Eurosat: A noveldataset and deep learning benchmark for land use and land coverclassification,” IEEE Journal of Selected Topics in Applied EarthObservations and Remote Sensing, vol. 12, pp. 2217–2226, 2019.
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. Jawahar, “Cats anddogs,” in CVPR, 2012.
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi,“Fine-grained visual classification of aircraft,” arXiv preprintarXiv:1306.5151, 2013.
L. Bossard, M. Guillaumin, and L. V. Gool, “Food-101–mining discriminativecomponents with random forests,” in ECCV, 2014.
M.-E. Nilsback and A. Zisserman, “Automated flower classification overa large number of classes,” in ICVGIP, 2008.
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3d object representationsfor fine-grained categorization,” in ICCVW, 2013.
J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, “Sundatabase: Large-scale scene recognition from abbey to zoo,” in CVPR,2010.
K. Soomro, “Ucf101: A dataset of 101 human actions classes fromvideos in the wild,” arXiv preprint arXiv:1212.0402, 2012.
B. Recht, R. Roelofs, L. Schmidt, and V. Shankar, “Do imagenetclassifiers generalize to imagenet?” in ICML, 2019.
H. Wang, S. Ge, Z. Lipton, and E. P. Xing, “Learning robust globalrepresentations by penalizing local predictive power,” NeurIPS, 2019.
D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song, “Naturaladversarial examples,” in CVPR, 2021.
D. Hendrycks, S. Basart, N. Mu, S. Kadavath, F. Wang, E. Dorundo,R. Desai, T. Zhu, S. Parajuli, M. Guo et al., “The many faces ofrobustness: A critical analysis of out-of-distribution generalization,” inICCV, 2021.
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier,and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrasecorrespondences for richer image-to-sentence models,” in ICCV, 2015.
L. Yu, P. Poirson, S. Yang, A. C. Berg, and T. L. Berg, “Modelingcontext in referring expressions,” in ECCV, 2016.
N. Xie, F. Lai, D. Doran, and A. Kadav, “Visual entailment: Anovel task for fine-grained image understanding,” arXiv preprintarXiv:1901.06706, 2019.
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson,K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., “Flamingo: avisual language model for few-shot learning,” NeurIPS, 2022.
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman,D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4technical report,” arXiv preprint arXiv:2303.08774, 2023.
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping languageimagepre-training with frozen image encoders and large languagemodels,” in ICML, 2023.
Y. Chen, E. Mendes, S. Das, W. Xu, and A. Ritter, “Can languagemodels be instructed to protect personal information?” arXiv preprintarXiv:2310.02224, 2023.
H. Tu, C. Cui, Z. Wang, Y. Zhou, B. Zhao, J. Han, W. Zhou, H. Yao,and C. Xie, “How many unicorns are in this image? a safety evaluationbenchmark for vision llms,” in ECCV, 2024.
X. Liu, Y. Zhu, J. Gu, Y. Lan, C. Yang, and Y. Qiao, “Mm-safetybench:A benchmark for safety evaluation of multimodal large language models,”in ECCV, 2024.
H. Zhang, W. Shao, H. Liu, Y. Ma, P. Luo, Y. Qiao, andK. Zhang, “Avibench: Towards evaluating the robustness of large visionlanguagemodel on adversarial visual-instructions,” arXiv preprintarXiv:2403.09346, 2024.
Z. Ying, A. Liu, X. Liu, and D. Tao, “Unveiling the safety ofgpt-4o: An empirical study using jailbreak attacks,” arXiv preprintarXiv:2406.06302, 2024.
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “Highresolutionimage synthesis with latent diffusion models,” in CVPR,2022.
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchicaltext-conditional image generation with clip latents,” arXiv preprintarXiv:2204.06125, 2022.
J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang,J. Zhuang, J. Lee, Y. Guo et al., “Improving image generation with bettercaptions,” Computer Science. https://cdn. openai. com/papers/dalle-3. pdf, vol. 2, no. 3, p. 8, 2023.
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton,K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al.,“Photorealistic text-to-image diffusion models with deep language understanding,”NeurIPS, 2022.
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilisticmodels,” NeurIPS, 2020.
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,”in ICLR, 2021.
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon,and B. Poole, “Score-based generative modeling through stochasticdifferential equations,” in ICLR, 2021.
D. Yang, Y. Bai, X. Jia, Y. Liu, X. Cao, and W. Yu, “On the multi-modalvulnerability of diffusion models,” in TiFA, 2024.
Y.-L. Tsai, C.-Y. Hsu, C. Xie, C.-H. Lin, J. Y. Chen, B. Li, P.-Y. Chen,C.-M. Yu, and C.-Y. Huang, “Ring-a-bell! how reliable are conceptremoval methods for diffusion models?” in ICLR, 2024.
M. Fuchi and T. Takagi, “Erasing concepts from text-to-image diffusionmodels with few-shot unlearning,” arXiv preprint arXiv:2405.07288,2024.
K. Meng, A. S. Sharma, A. Andonian, Y. Belinkov, and D. Bau, “Masseditingmemory in a transformer,” in ICLR, 2023.
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang,H. Su, J. Zhu et al., “Grounding dino: Marrying dino with groundedpre-training for open-set object detection,” in ECCV, 2024.
D. Chen, N. Yu, Y. Zhang, and M. Fritz, “Gan-leaks: A taxonomy ofmembership inference attacks against generative models,” in CCS, 2020.
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Imagequality assessment: from error visibility to structural similarity,” IEEEtransactions on Image Processing, vol. 13, pp. 600–612, 2004.
B. Qu et al., “Very simple membership inference and synthetic identificationin denoising diffusion models,” Ph.D. dissertation, VanderbiltUniversity, 2024.
G. Somepalli, V. Singla, M. Goldblum, J. Geiping, and T. Goldstein,“Understanding and mitigating copying in diffusion models,” NeurIPS,2023.
X. Gu, C. Du, T. Pang, C. Li, M. Lin, and Y. Wang, “On memorizationin diffusion models,” arXiv preprint arXiv:2310.02664, 2023.
Y. Wen, Y. Liu, C. Chen, and L. Lyu, “Detecting, explaining, andmitigating memorization in diffusion models,” in ICLR, 2024.
J. Ren, Y. Li, S. Zeng, H. Xu, L. Lyu, Y. Xing, and J. Tang, “Unveilingand mitigating memorization in text-to-image diffusion models throughcross attention,” in ECCV, 2024.
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang,and W. Chen, “Lora: Low-rank adaptation of large language models,”in ICLR, 2022.
G. W. Stewart, “On the early history of the singular value decomposition,”SIAM review, vol. 35, pp. 551–566, 1993.
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot,D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier et al.,“Mistral 7b,” arXiv preprint arXiv:2310.06825, 2023.
Z. Jiang, J. Zhang, and N. Z. Gong, “Evading watermark based detectionof ai-generated content,” in Proceedings of the 2023 ACM SIGSACConference on Computer and Communications Security, 2023, pp.1168–1181.
Y. Hu, Z. Jiang, M. Guo, and N. Gong, “A transfer attack to imagewatermarks,” arXiv preprint arXiv:2403.15365, 2024.
——, “Stable signature is unstable: Removing image watermark fromdiffusion models,” arXiv preprint arXiv:2405.07145, 2024.
C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis,A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki, “Laion-400m:Open dataset of clip-filtered 400 million image-text pairs,” arXivpreprint arXiv:2111.02114, 2021.
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman,M. Cherti, T. Coombes, A. Katta, C. Mullis, M.Wortsman et al., “Laion-5b: An open large-scale dataset for training next generation image-textmodels,” NeurIPS, 2022.
Z. J. Wang, E. Montoya, D. Munechika, H. Yang, B. Hoover, and D. H.Chau, “Diffusiondb: A large-scale prompt gallery dataset for text-toimagegenerative models,” arXiv preprint arXiv:2210.14896, 2022.
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet:A large-scale hierarchical image database,” in 2009 IEEE conference oncomputer vision and pattern recognition. Ieee, 2009, pp. 248–255.
A. Krizhevsky, G. Hinton et al., “Learning multiple layers of featuresfrom tiny images,” 2009.
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes inthe wild,” in ICCV, 2015.
Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman, “Vggface2:A dataset for recognising faces across pose and age,” in FG, 2018.
N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, and K. Aberman,“Dreambooth: Fine tuning text-to-image diffusion models for subjectdrivengeneration,” in CVPR, 2023.
J. N. M. Pinkney, “Pokemon blip captions,” https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions/, 2022.
B. Saleh and A. Elgammal, “Large-scale classification of fine-artpaintings: Learning the right metric on the right feature,” arXiv preprintarXiv:1505.00855, 2015.
L. M. Titus, “Does chatgpt have semantic understanding? a problemwith the statistics-of-occurrence strategy,” Cognitive Systems Research,vol. 83, p. 101174, 2024.
W.-L. Chiang, L. Zheng, Y. Sheng, A. N. Angelopoulos, T. Li, D. Li,B. Zhu, H. Zhang, M. Jordan, J. E. Gonzalez et al., “Chatbot arena:An open platform for evaluating llms by human preference,” in ICML,2024.
R. Greenblatt, C. Denison, B. Wright, F. Roger, M. MacDiarmid,S. Marks, J. Treutlein, T. Belonax, J. Chen, D. Duvenaudet al., “Alignment faking in large language models,” arXiv preprintarXiv:2412.14093, 2024.
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark,A. Ostrow, A. Welihinda, A. Hayes, A. Radford et al., “Gpt-4o systemcard,” arXiv preprint arXiv:2410.21276, 2024.
X. Qi, A. Panda, K. Lyu, X. Ma, S. Roy, A. Beirami, P. Mittal, and P. Henderson, “Safety alignment should be made more than just a fewtokens deep,” in ICLR, 2025.
W. Zhao, Z. Li, Y. Li, Y. Zhang, and J. Sun, “Defending large language models against jailbreak attacks via layer-specific editing,” in EMNLP,2024.
S. Li, L. Yao, L. Zhang, and Y. Li, “Safety layers in alignedlarge language models: The key to llm security,” arXiv preprintarXiv:2408.17003, 2024.
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptivemixtures of local experts,” Neural Computation, 1991.
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton,and J. Dean, “Outrageously large neural networks: The sparsely-gatedmixture-of-experts layer,” in ICLR, 2017.
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling totrillion parameter models with simple and efficient sparsity,” JMLR,2022.
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford,D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand et al.,“Mixtral of experts,” arXiv preprint arXiv:2401.04088, 2024.
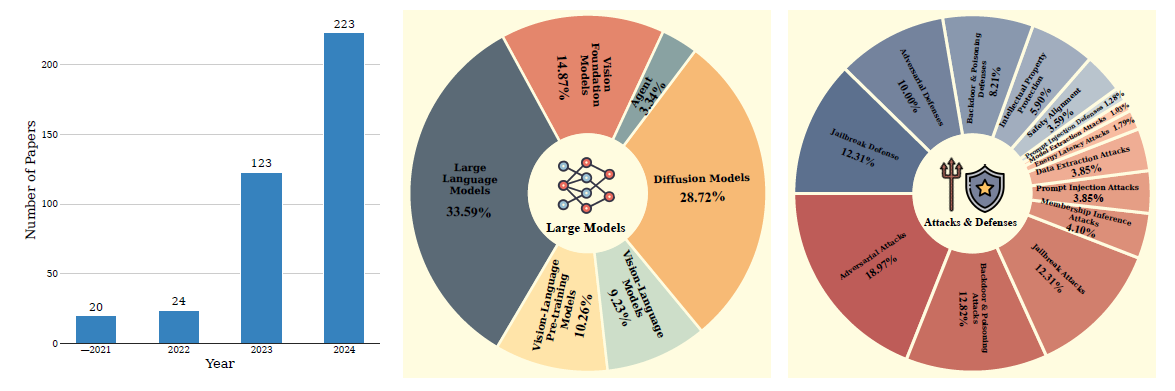
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2025 Kris Carlson

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.

