
GDPVAL: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
DOI:
https://doi.org/10.70777/si.v2i4.17197Keywords:
Frontier models, ai benchmarks, AI model performance , U.S. Bureau of Labor Statistics, Human expert grading, Economically valuable tasks, job displacement, artificial general intelligence, Real-world work activities, Multimodal capabilitiesAbstract
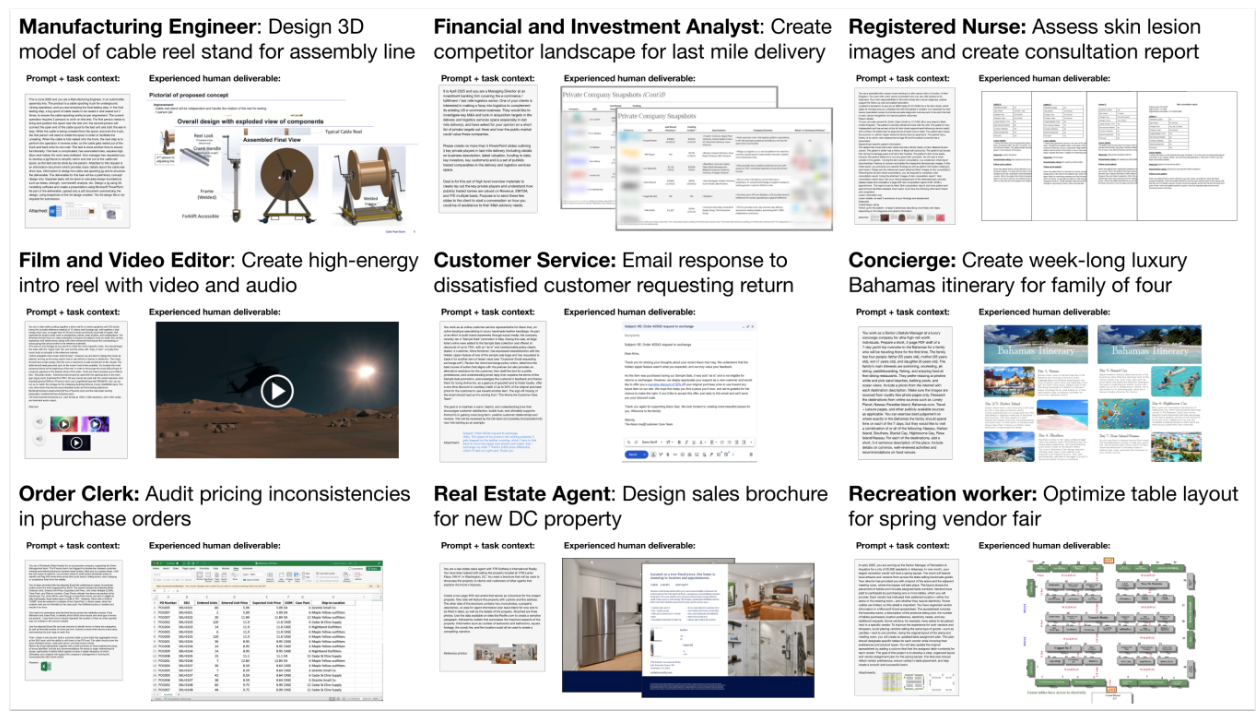
We introduce GDPval, a benchmark evaluating AI model capabilities on realworld economically valuable tasks. GDPval covers the majority of U.S. Bureau of Labor Statistics Work Activities for 44 occupations across the top 9 sectors contributing to U.S. GDP (Gross Domestic Product). Tasks are constructed from the representative work of industry professionals with an average of 14 years of experience. We find that frontier model performance on GDPval is improving roughly linearly over time, and that the current best frontier models are approaching industry experts in deliverable quality. We analyze the potential for frontier models, when paired with human oversight, to perform GDPval tasks cheaper and faster than unaided experts. We also demonstrate that increased reasoning effort, increased task context, and increased scaffolding improves model performance on GDPval. Finally, we open-source a gold subset of 220 tasks and provide a public automated grading service at evals.openai.com to facilitate future research in understanding real-world model capabilities.
References
Daron Acemoglu. The simple macroeconomics of ai. Economic Policy, 40(121):13–58, 2025.
Daron Acemoglu and David Autor. Skills, tasks and technologies: Implications for employment and earnings. In Handbook of labor economics, volume 4, pp. 1043–1171. Elsevier, 2011.
Ruth Appel, Peter McCrory, Alex Tamkin, Michael Stern, Miles McCain, and Tyler Neylon. Anthropic economic index report: Uneven geographic and enterprise ai adoption. Anthropic Research,2025. URL https://www.anthropic.com/research/anthropic-economic-index-september-2025-report.
Alexander Bick, Adam Blandin, and David J Deming. The rapid adoption of generative ai. Technical report, National Bureau of Economic Research, 2024.
Erik Brynjolfsson and Lorin M. Hitt. Beyond computation: Information technology, organizational transformation and business performance. Journal of Economic Perspectives, 14(4):23–48, 2000.doi: 10.1257/jep.14.4.23. URL https://www.aeaweb.org/articles?id=10.1257/jep.14.4.23.
Erik Brynjolfsson, Daniel Rock, and Chad Syverson. Artificial intelligence and the modern productivity paradox: A clash of expectations and statistics. Working Paper 24001, National Bureau ofEconomic Research, November 2017. URL http://www.nber.org/papers/w24001.
Erik Brynjolfsson, Danielle Li, and Lindsey Raymond. Generative ai at work. The Quarterly Journalof Economics, 140(2):889–942, 2025.
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl YanShan, and Kevin Wadman. How people use chatgpt. Working Paper 34255, National Bureau of Economic Research, September 2025. URL http://www.nber.org/papers/w34255.Wilbur
Xinyuan Chen, Suraj Srinivasan, and Saleh Zakerinia. Displacement or complementarity?: The labor market impact of generative ai. Harvard Business School, 2025.
Paul A. David. The dynamo and the computer: An historical perspective on the modern productivity paradox. American Economic Review, 80(2):355–361, 1990. URL https://econpapers.repec.org/RePEc:aea:aecrev:v:80:y:1990:i:2:p:355-61.
Yogesh K Dwivedi, Laurie Hughes, Elvira Ismagilova, Gert Aarts, Crispin Coombs, Tom Crick, Yanqing Duan, Rohita Dwivedi, John Edwards, Aled Eirug, et al. Artificial intelligence (ai):Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. International journal of information management, 57:101994, 2021.
Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock. Gpts are gpts: An early look at the labor market impact potential of large language models, 2023. URL https://arxiv.org/abs/2303.10130.
Federal Reserve Bank of St. Louis. Value added by industry as a percentage of gross domesticproduct. FRED Release Tables, 2025. URL https://fred.stlouisfed.org/release/tables?rid=331&eid=211. Accessed: 2025-09-03.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, andJacob Steinhardt. Measuring massive multitask language understanding. arXiv preprintarXiv:2009.03300, 2020. doi: 10.48550/arXiv.2009.03300. URL https://arxiv.org/abs/2009.03300.10
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding,Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688, 2023. doi:10.48550/arXiv.2308.03688.
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Canfrontier LLMs earn $1 million from real-world freelance software engineering? arXiv preprintarXiv:2502.12115, 2025.
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. Llm evaluators recognize and favor theirown generations, 2024. URL https://arxiv.org/abs/2404.13076.Long Phan et al. Humanity’s last exam. arXiv preprint arXiv:2501.14249, 2025.
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, JulienDirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023. doi: 10.48550/arXiv.2311.12022. URLhttps://arxiv.org/abs/2311.12022.
Robert M. Solow. We’d better watch out. New York Times Book Review, pp. 36, July 1987. URLhttps://www.standupeconomist.com/pdf/misc/solow-computer-productivity.pdf.
Alex Tamkin, Miles McCain, Kunal Handa, Esin Durmus, Liane Lovitt, Ankur Rathi, Saffron Huang, Alfred Mountfield, Jerry Hong, Stuart Ritchie, Michael Stern, Brian Clarke, Landon Goldberg, Theodore R. Sumers, Jared Mueller, William McEachen, Wes Mitchell, Shan Carter, Jack Clark, Jared Kaplan, and Deep Ganguli. Clio: Privacy-preserving insights into real-worldai use. arXiv preprint arXiv:2412.13678, 2024. doi: 10.48550/arXiv.2412.13678. URLhttps://arxiv.org/abs/2412.13678.
U.S. Bureau of Labor Statistics. Occupational outlook – occupational data. https://www.bls.gov/emp/data/occupational-data.htm, 2025a. Accessed: 2025-09-03.
U.S. Bureau of Labor Statistics. Occupational employment and wage statistics: May 2024 national tables. https://www.bls.gov/oes/tables.htm, 2025b. Data reference May 2024;accessed: 2025-09-03.U.S. Department of Labor, Employment and Training Administration. Work activities - onet 28.3data dictionary. https://www.onetcenter.org/dictionary/28.3/excel/task_ratings.html, 2024. Accessed: 2025-04-20.A
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2026 Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Sim´on Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, Natalie S. Kim, Patrick Chao, Samuel Miserendino, Gildas Chabot, David Li, Michael Sharman, Alexandra Barr, Amelia Glaese, Jerry Tworek

This work is licensed under a Creative Commons Attribution 4.0 International License.

