
What AI evaluations for preventing catastrophic risk can and cannot do
DOI:
https://doi.org/10.70777/si.v2i4.17167Keywords:
ai model capabilities, ai catastropic risks, agi governance, agi risk assessment, ai limitations, agi safety, agi value alignment, ai emergent behavior, agi precursor capabilities, ai risk taxonomy, ai capabilities lower boundsAbstract
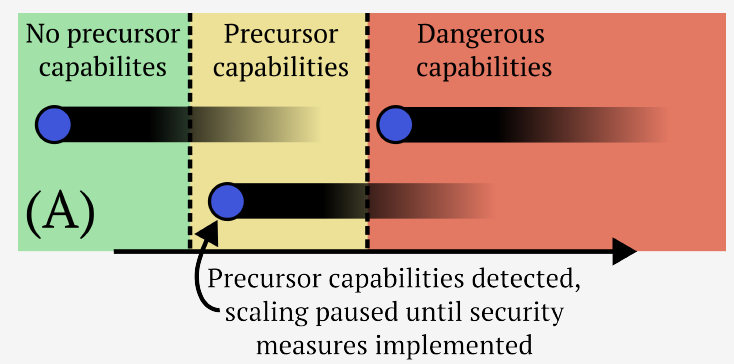
AI evaluations are an important component of the AI governance toolkit, underlying current approaches to safety cases for preventing catastrophic risks. Our paper examines what these evaluations can and cannot tell us. Evaluations can establish lower bounds on AI capabilities and assess certain misuse risks given sufficient effort from evaluators.
Unfortunately, evaluations face fundamental limitations that cannot be overcome within the current paradigm. These include an inability to establish upper bounds on capabilities, reliably forecast future model capabilities, or robustly assess risks from autonomous AI systems. This means that while evaluations are valuable tools, we should not rely on them as our main way of ensuring AI systems are safe. We conclude with recommendations for incremental improvements to frontier AI safety, while acknowledging these fundamental limitations remain unsolved
References
Peter Barnett and Lisa Thiergart. Declare and justify: Explicit assumptions in ai evaluations are necessary for effective regulation. arXiv preprint arXiv:2411.12820, 2024.
Joshua Clymer, Nick Gabrieli, David Krueger, and Thomas Larsen. Safety Cases: How to Justify the Safety of Advanced AI Systems, March 2024. arXiv:2403.10462 [cs].
Arthur Goemans, Marie Davidsen Buhl, Jonas Schuett, Tomek Korbak, Jessica Wang, Benjamin Hilton, and Geoffrey Irving. Safety case template for frontier ai: A cyber inability argument. arXiv preprint arXiv:2411.08088, 2024.
Anthropic. Anthropic’s Responsible Scaling Policy Version 1.0, 2023.
OpenAI. Preparedness Framework (Beta), 2023.
Google Deepmind. Frontier Safety Framework, 2024.
Mary Phuong, Matthew Aitchison, Elliot Catt, Sarah Cogan, Alexandre Kaskasoli, Victoria Krakovna, David Lindner, Matthew Rahtz, Yannis Assael, Sarah Hodkinson, Heidi Howard, 8 Tom Lieberum, Ramana Kumar, Maria Abi Raad, Albert Webson, Lewis Ho, Sharon Lin, Sebastian Farquhar, Marcus Hutter, Gregoire Deletang, Anian Ruoss, Seliem El-Sayed, Sasha Brown, Anca Dragan, Rohin Shah, Allan Dafoe, and Toby Shevlane. Evaluating Frontier Models for Dangerous Capabilities, April 2024. arXiv:2403.13793 [cs].
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. Llm agents can autonomously hack websites. arXiv preprint arXiv:2402.06664, 2024.
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. LLM Agents can Autonomously Exploit One-day Vulnerabilities, April 2024. arXiv:2404.08144 [cs].
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. Teams of LLM Agents can Exploit Zero-Day Vulnerabilities, June 2024. arXiv:2406.01637 [cs].
Francesco Salvi, Manoel Horta Ribeiro, Riccardo Gallotti, and Robert West. On the Conversational Persuasiveness of Large Language Models: A Randomized Controlled Trial, March 2024. arXiv:2403.14380 [cs].
S. C. Matz, J. D. Teeny, S. S. Vaid, H. Peters, G. M. Harari, and M. Cerf. The potential of generative AI for personalized persuasion at scale. Scientific Reports, 14(1):4692, February 2024.
Stephen Casper, Carson Ezell, Charlotte Siegmann, Noam Kolt, Taylor Lynn Curtis, Benjamin Bucknall, Andreas Haupt, Kevin Wei, Jeremy Scheurer, Marius Hobbhahn, Lee Sharkey, Satyapriya Krishna, Marvin Von Hagen, Silas Alberti, Alan Chan, Qinyi Sun, Michael Gerovitch, David Bau, Max Tegmark, David Krueger, and Dylan Hadfield-Menell. Black-Box Access is Insufficient for Rigorous AI Audits. In The 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 2254–2272, June 2024. arXiv:2401.14446 [cs].
Sella Nevo, Dan Lahav, Ajay Karpur, Yogev Bar-On, and Henry Alexander Bradley. Securing AI Model Weights: Preventing Theft and Misuse of Frontier Models. Number 1. Rand Corporation, 2024.
Carl Franzen. Mistral CEO confirms ‘leak’ of new open source AI model nearing GPT-4 performance. https://venturebeat.com/ai/ mistral-ceo-confirms-leak-of-new-open-source-ai-model-nearing-gpt-4-performance/, 2024. [Accessed 22-11-2024].
Jide Alaga and Jonas Schuett. Coordinated pausing: An evaluation-based coordination scheme for frontier ai developers. arXiv preprint arXiv:2310.00374, 2023.
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cornelius Aschermann, Yaohui Chen, Dhaval Kapil, et al. Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models. arXiv preprint arXiv:2404.13161, 2024.
Sergei Glazunov and Mark Brand. Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models. https://googleprojectzero.blogspot.com/2024/06/ project-naptime.html, 2024. [Accessed 22-11-2024].
Tom Davidson, Jean-Stanislas Denain, Pablo Villalobos, and Guillem Bas. AI capabilities can be significantly improved without expensive retraining. arXiv preprint arXiv:2312.07413, 2023.
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024.
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench leaderboard. https://www.swebench.com/, 2024. [Accessed 22-11-2024].
Hugging Face. GAIA Leaderboard - a Hugging Face Space by gaia-benchmark. https: //huggingface.co/spaces/gaia-benchmark/leaderboard. [Accessed 25-11-2024]. 9
Papers with Code. HumanEval Benchmark (Code Generation). https://paperswithcode. com/sota/code-generation-on-humaneval. [Accessed 25-11-2024].
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1107–1128, 2024. [25] Anthropic. Anthropic’s Responsible Scaling Policy, 2024.
Marius Hobbhahn. We need a Science of Evals. https://www.apolloresearch.ai/blog/ we-need-a-science-of-evals. [Accessed 12-09-2024].
Teun van der Weij, Felix Hofstatter, Ollie Jaffe, Samuel F. Brown, and Francis Rhys Ward. AI Sandbagging: Language Models can Strategically Underperform on Evaluations, June 2024. arXiv:2406.07358 [cs]
Ryan Greenblatt, Fabien Roger, Dmitrii Krasheninnikov, and David Krueger. Stress-testing capability elicitation with password-locked models. arXiv preprint arXiv:2405.19550, 2024.
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2026 Peter Barnett, Lisa Thiergart

This work is licensed under a Creative Commons Attribution 4.0 International License.

