
Standardizing Intelligence: Aligning Generative AI for Regulatory and Operational Compliance
DOI:
https://doi.org/10.70777/si.v2i5.16189Keywords:
Generative AI (GenAI); Technical Standards; Regulatory Compliance; Operational Compliance; Conformity Assessment; Standard Alignment; Criticality Levels; Domain Knowledge Dependency; Model Development Complexity; CRITICALITY AND COMPLIANCE CAPABILITIES FRAMEWORK (C3F); Instruction Tuning; Reinforcement Learning (RL); In-Context Learning (ICL); Synthetic Data Generation; Retrieval-Augmented Generation (RAG); Reasoning Capabilities; Standard Developing Organizations (SDOs); Interoperability; Human Expert Oversight; Standard ComplianceAbstract
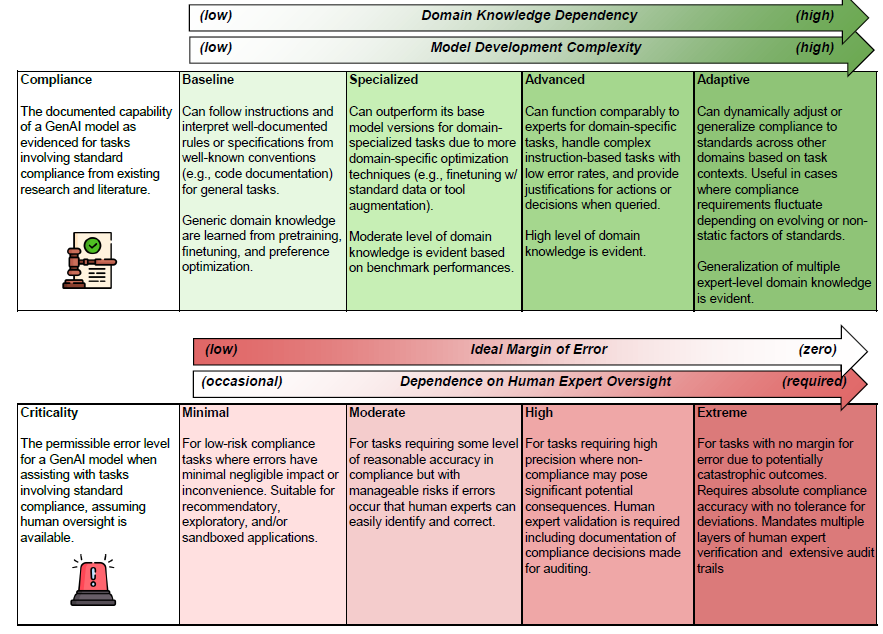
Technical standards, or simply standards, are established documented guidelines and rules that facilitate the interoperability, quality, and accuracy of systems and processes. In recent years, we have witnessed an emerging paradigm shift where the adoption of generative AI (GenAI) models has increased tremendously, spreading implementation interests across standard-driven industries, including engineering, legal, healthcare, and education. In this paper, we assess the criticality levels of different standards across domains and sectors and complement them by grading the current compliance capabilities of state-of-the-art GenAI models. To support the discussion, we outline possible challenges and opportunities with integrating GenAI for standard compliance tasks while also providing actionable recommendations for entities involved with developing and using standards. Overall, we argue that aligning GenAI with standards through computational methods can help strengthen regulatory and operational compliance. We anticipate this area of research will play a central role in the management, oversight, and trustworthiness of larger, more powerful GenAI-based systems in the near future.
References
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida,J. Altenschmidt, S. Altman, S. Anadkat, et al. GPT-4 Technical Report. arXiv preprintarXiv:2303.08774, 2023. URL https://arxiv.org/abs/2303.08774.
Act. Health Insurance Portability and Accountability Act of 1996. Public law, 104:191, 1996.URL http://www.eolusinc.com/pdf/hipaa.pdf.
P. Aghion, A. Bergeaud, and J. Van Reenen. The impact of regulation on innovation. AmericanEconomic Review, 113(11):2894–2936, 2023. URL https://www.aeaweb.org/articles?id=10.1257/aer.20210107. DOI: https://doi.org/10.1257/aer.20210107
F. Albuquerque and P. Gomes Dos Santos. Exploring ChatGPT’s capabilities in solvingaccounting standards problems: the case of IAS 37. Cogent Education, 11(1):2412492, 2024.URL https://www.tandfonline.com/doi/pdf/10.1080/2331186X.2024.2412492#page=14.85. DOI: https://doi.org/10.1080/2331186X.2024.2412492
ASD-STE100. ASD-STE100 Simplified Technical English. Simplified Technical EnglishMaintenance Group (STEMG), issue 9 edition, Jan. 2025. URL https://www.asd-ste100.org/.
ASTM International. Form and Style for ASTM Standards, 2025. URL https://www.astm.org/form-style-for-astm-stds.html. Accessed: 2025-01-23.
R. Beer, A. Feix, T. Guttzeit, T. Muras, V. Müller, M. Rauscher, F. Schäffler, and W. Löwe.Examination of Code generated by Large Language Models. arXiv preprint arXiv:2408.16601,2024. URL https://arxiv.org/pdf/2408.16601.
A. Berger, L. Hillebrand, D. Leonhard, T. Deuser, T. B. F. De Oliveira, T. Dilmaghani,M. Khaled, B. Kliem, R. Loitz, C. Bauckhage, et al. Towards Automated Regulatory ComplianceVerification in Financial Auditing with Large Language Models. In 2023 IEEEInternational Conference on Big Data (BigData), pages 4626–4635. IEEE Computer Society,2023. URL https://www.computer.org/csdl/pds/api/csdl/proceedings/download-article/1TUOuabhdXq/pdf. DOI: https://doi.org/10.1109/BigData59044.2023.10386518
J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo,et al. Improving Image Generation with Better Captions. Computer Science, 2(3):8, 2023.URL https://cdn.openai.com/papers/dall-e-3.pdf.
S. R. Bowman, J. Hyun, E. Perez, E. Chen, C. Pettit, S. Heiner, K. Lukoši¯ut˙e, A. Askell,A. Jones, A. Chen, et al. Measuring Progress on Scalable Oversight for Large Language Models.arXiv preprint arXiv:2211.03540, 2022. URL https://arxiv.org/abs/2211.03540.
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan,P. Shyam, G. Sastry, A. Askell, et al. Language Models are Few-Shot Learners. Advances inNeural Information Processing Systems, 33:1877–1901, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
BSI Group. Standards terminology: When is a standard no longer a standard?, 2024. URLhttps://knowledge.bsigroup.com/articles/standards-terminology-when-is-a-standard-no-longer-a-standard. Accessed: 2025-01-20.
C. Burns, P. Izmailov, J. H. Kirchner, B. Baker, L. Gao, L. Aschenbrenner, Y. Chen, A. Ecoffet,M. Joglekar, J. Leike, et al. Weak-to-Strong Generalization: Eliciting Strong Capabilities WithWeak Supervision. In Forty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=ghNRg2mEgN.
Z. Chen, A. H. Cano, A. Romanou, A. Bonnet, K. Matoba, F. Salvi, M. Pagliardini, S. Fan,A. Köpf, A. Mohtashami, et al. MEDITRON-70B: Scaling Medical Pretraining for LargeLanguage Models. arXiv preprint arXiv:2311.16079, 2023. URL https://arxiv.org/abs/2311.16079.
W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y. Zhuang,J. E. Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgptquality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
W.-L. Chiang, L. Zheng, Y. Sheng, A. N. Angelopoulos, T. Li, D. Li, B. Zhu, H. Zhang,M. Jordan, J. E. Gonzalez, et al. Chatbot Arena: An Open Platform for Evaluating LLMs byHuman Preference. In Forty-first International Conference on Machine Learning, 2023. URLhttps://openreview.net/forum?id=3MW8GKNyzI.
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W.Chung, C. Sutton, S. Gehrmann, et al. PaLM: Scaling Language Modeling with Pathways.Journal of Machine Learning Research, 24(240):1–113, 2023. URL https://www.jmlr.org/papers/v24/22-1144.html.
H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, Y. Li, X. Wang, M. Dehghani,S. Brahma, et al. Scaling Instruction-Finetuned Language Models. Journal of MachineLearning Research, 25(70):1–53, 2024.
M. Coeckelbergh. Artificial Intelligence, Responsibility Attribution, and a Relational Justificationof Explainability. Science and Engineering Ethics, 26(4):2051–2068, 2020. URLhttps://link.springer.com/content/pdf/10.1007/s11948-019-00146-8. DOI: https://doi.org/10.1007/s11948-019-00146-8
P. Colombo, T. Pires, M. Boudiaf, R. F. C. P. de Melo, G. Hautreux, E. Malaboeuf, J. Charpentier,D. Culver, and M. Desa. SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptationfor the Legal Domain. In The Thirty-eighth Annual Conference on Neural Information ProcessingSystems, 2024. URL https://openreview.net/forum?id=NLUYZ4ZqNq.
A. Creswell and M. Shanahan. Faithful Reasoning Using Large Language Models. arXivpreprint arXiv:2208.14271, 2022. URL https://arxiv.org/abs/2208.14271.
I. da Cunha. Un redactor asistido para adaptar textos administrativos a lenguaje claro. Procesamientodel Lenguaje Natural, 69:39–49, 2022. URL http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6426.
M. de Costa, M. Anwar, D. Lau, and I. Hammad. Classification of Safety Events at NuclearSites using Large Language Models. arXiv preprint arXiv:2409.00091, 2024. URL https://arxiv.org/pdf/2409.00091.
D. Demortain. Standardising through concepts: The power of scientific experts in internationalstandard-setting. Science and Public Policy, 35(6):391–402, 2008. URL https://academic.oup.com/spp/article/35/6/391/1673768. DOI: https://doi.org/10.3152/030234208X323325
Department for Education. Generative AI in education: educator and expert views. Governmentreport, Department for Education, 1 2024. URL https://www.gov.uk/government/publications/generative-ai-in-education-educator-and-expert-views.
N. Digital. Standard for Creating Health Content, 2025. URL https://service-manual.nhs.uk/content/standard-for-creating-health-content. Accessed: 2025-01-21.
EE Times. When Standards Change, 2018. URL https://www.eetimes.com/when-standards-change/. Accessed: 2025-01-20.
U. Ehsan, P. Tambwekar, L. Chan, B. Harrison, and M. O. Riedl. Automated RationaleGeneration: A Technique for Explainable AI and its Effects on Human Perceptions. InProceedings of the 24th International Conference on Intelligent User Interfaces, pages 263–274, 2019. URL https://dl.acm.org/doi/abs/10.1145/3301275.3302316. DOI: https://doi.org/10.1145/3301275.3302316
F. Eiras, A. Petrov, B. Vidgen, C. Schroeder De Witt, F. Pizzati, K. Elkins, S. Mukhopadhyay,A. Bibi, B. Csaba, F. Steibel, F. Barez, G. Smith, G. Guadagni, J. Chun, J. Cabot, J. M. Imperial,J. A. Nolazco-Flores, L. Landay, M. T. Jackson, P. Rottger, P. Torr, T. Darrell, Y. S. Lee, and J. N.Foerster. Position: Near to Mid-term Risks and Opportunities of Open-Source Generative AI.In R. Salakhutdinov, Z. Kolter, K. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp,editors, Proceedings of the 41st International Conference on Machine Learning, volume 235of Proceedings of Machine Learning Research, pages 12348–12370. PMLR, 21–27 Jul 2024.URL https://proceedings.mlr.press/v235/eiras24b.html.
S. Elkins, E. Kochmar, J. C. Cheung, and I. Serban. How Teachers Can Use Large LanguageModels and Bloom’s Taxonomy to Create Educational Quizzes. In Proceedings of the AAAIConference on Artificial Intelligence, volume 38, pages 23084–23091, 2024. URL https://ojs.aaai.org/index.php/AAAI/article/download/30353/32395. DOI: https://doi.org/10.1609/aaai.v38i21.30353
W. Fan, H. Li, Z. Deng, W. Wang, and Y. Song. GoldCoin: Grounding large languagemodels in privacy laws via contextual integrity theory. In Y. Al-Onaizan, M. Bansal, andY.-N. Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in NaturalLanguage Processing, pages 3321–3343, Miami, Florida, USA, Nov. 2024. Association forComputational Linguistics. doi:10.18653/v1/2024.emnlp-main.195. URL https://aclanthology.org/2024.emnlp-main.195/. DOI: https://doi.org/10.18653/v1/2024.emnlp-main.195
I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, S. Kim, F. Dernoncourt, T. Yu, R. Zhang,and N. K. Ahmed. Bias and Fairness in Large Language Models: A Survey. ComputationalLinguistics, 50(3):1097–1179, 09 2024. ISSN 0891-2017. doi:10.1162/coli_a_00524. URLhttps://doi.org/10.1162/coli_a_00524. DOI: https://doi.org/10.1162/coli_a_00524
D. Glandorf and D. Meurers. Towards Fine-Grained Pedagogical Control over EnglishGrammar Complexity in Educational Text Generation. In E. Kochmar, M. Bexte, J. Burstein,A. Horbach, R. Laarmann-Quante, A. Tack, V. Yaneva, and Z. Yuan, editors, Proceedings of the19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024),pages 299–308, Mexico City, Mexico, June 2024. Association for Computational Linguistics.URL https://aclanthology.org/2024.bea-1.24/.
M. Y. Guan, M. Joglekar, E. Wallace, S. Jain, B. Barak, A. Heylar, R. Dias, A. Vallone, H. Ren,J. Wei, et al. Deliberative Alignment: Reasoning Enables Safer Language Models. arXivpreprint arXiv:2412.16339, 2024. URL https://arxiv.org/abs/2412.16339. DOI: https://doi.org/10.70777/si.v2i3.15159
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P.Wang, X. Bi, X. Zhang,X. Yu, Y.Wu, Z.Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B.Wang, B.Wu, B. Feng,C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai,F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Ding, H. Xin, H. Gao,H. Qu, H. Li, J. Guo, J. Li, J. Wang, J. Chen, J. Yuan, J. Qiu, J. Li, J. Cai, J. Ni, J. Liang,J. Chen, K. Dong, K. Hu, K. Gao, K. Guan, K. Huang, K. Yu, L. Wang, L. Zhang, L. Zhao,L. Wang, L. Zhang, L. Xu, L. Xia, M. Zhang, M. Zhang, M. Tang, M. Li, M. Wang, M. Li,N. Tian, P. Huang, P. Zhang, Q. Wang, Q. Chen, Q. Du, R. Ge, R. Zhang, R. Pan, R. Wang,R. Chen, R. Jin, R. Chen, S. Lu, S. Zhou, S. Chen, S. Ye, S.Wang, S. Yu, S. Zhou, S. Pan, S. Li,et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement LearningarXiv preprint arXiv:2501.12948, 2025. URL https://arxiv.org/abs/2501.12948. DOI: https://doi.org/10.1038/s41586-025-09422-z
J. Guo, H. Chen, C. Wang, K. Han, C. Xu, and Y. Wang. Vision Superalignment: Weak-to-Strong Generalization for Vision Foundation Models. arXiv preprint arXiv:2402.03749, 2024.URL https://arxiv.org/abs/2402.03749.
S. Hao, T. Liu, Z. Wang, and Z. Hu. ToolkenGPT: Augmenting Frozen Language Models withMassive Tools via Tool Embeddings. Advances in Neural Information Processing Systems 36(NeurIPS 2023), 36:45870–45894, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/8fd1a81c882cd45f64958da6284f4a3f-Abstract-Conference.html.
Y. Hashem, S. Esnaashari, D. Morgan, J. Francis, A. Poletaev, F. Enock, and J. Bright. One inFour UK Doctors Are Using Artificial Intelligence: Exploring Doctors’ Perspectives on AIAfter the Emergence of Large Language Models, 2024. URL https://www.turing.ac.uk/news/publications/one-four-uk-doctors-are-using-artificial-intelligence. DOI: https://doi.org/10.2139/ssrn.4997033
J. Hernandez, D. Golpayegani, and D. Lewis. An Open Knowledge Graph-Based Approachfor Mapping Concepts and Requirements between the EU AI Act and International Standards.arXiv preprint arXiv:2408.11925, 2024. URL https://arxiv.org/abs/2408.11925. DOI: https://doi.org/10.31219/osf.io/y4mcj
C. Hildebrandt, T. Woodlief, and S. Elbaum. ODD-diLLMma: Driving Automation SystemODD Compliance Checking using LLMs. In 2024 IEEE/RSJ International Conference onIntelligent Robots and Systems (IROS), pages 13809–13816. IEEE, 2024. URL https://carl-h.com/assets/files/publications/IROS24-ODD.pdf. DOI: https://doi.org/10.1109/IROS58592.2024.10801369
K. Hirata, Y. Matsui, A. Yamada, T. Fujioka, M. Yanagawa, T. Nakaura, R. Ito, D. Ueda,S. Fujita, F. Tatsugami, et al. Generative AI and large language models in nuclear medicine:current status and future prospects. Annals of Nuclear Medicine, pages 1–12, 2024. URLhttps://link.springer.com/article/10.1007/s12149-024-01981-x. DOI: https://doi.org/10.1007/s12149-024-01981-x
J. Huang and K. C.-C. Chang. Towards Reasoning in Large Language Models: A Survey.In A. Rogers, J. Boyd-Graber, and N. Okazaki, editors, Findings of the Associationfor Computational Linguistics: ACL 2023, pages 1049–1065, Toronto, Canada, July 2023.Association for Computational Linguistics. doi:10.18653/v1/2023.findings-acl.67. URLhttps://aclanthology.org/2023.findings-acl.67/. DOI: https://doi.org/10.18653/v1/2023.findings-acl.67
J. M. Imperial and H. Tayyar Madabushi. Flesch or fumble? evaluating readability standardalignment of instruction-tuned language models. In S. Gehrmann, A. Wang, J. Sedoc, E. Clark,K. Dhole, K. R. Chandu, E. Santus, and H. Sedghamiz, editors, Proceedings of the ThirdWorkshop on Natural Language Generation, Evaluation, and Metrics (GEM), pages 205–223,Singapore, Dec. 2023. Association for Computational Linguistics. URL https://aclanthology.org/2023.gem-1.18/.
J. M. Imperial and H. Tayyar Madabushi. SpeciaLex: A Benchmark for In-Context SpecializedLexicon Learning. In Y. Al-Onaizan, M. Bansal, and Y.-N. Chen, editors, Findings of theAssociation for Computational Linguistics: EMNLP 2024, pages 930–965, Miami, Florida,USA, Nov. 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findingsemnlp.52. URL https://aclanthology.org/2024.findings-emnlp.52/. DOI: https://doi.org/10.18653/v1/2024.findings-emnlp.52
J. M. Imperial, G. Forey, and H. Tayyar Madabushi. Standardize: Aligning language modelswith expert-defined standards for content generation. In Y. Al-Onaizan, M. Bansal, andY.-N. Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in NaturalLanguage Processing, pages 1573–1594, Miami, Florida, USA, Nov. 2024. Association forComputational Linguistics. doi:10.18653/v1/2024.emnlp-main.94. URL https://aclanthology.org/2024.emnlp-main.94/. DOI: https://doi.org/10.18653/v1/2024.emnlp-main.94
International Organization for Standardization. Conformity Assessment. https://www.iso.org/conformity-assessment.html. Accessed: 2025-01-14.
International Organization for Standardization. Iso/iec 22989:2022 - information technology— artificial intelligence — artificial intelligence concepts and terminology, 2022. URLhttps://www.iso.org/standard/74296.html. Accessed: 2025-01-20.
ISO/IEC 27001:2022. Information security, cybersecurity and privacy protection — informationsecurity management systems— requirements, 2022.
H. Ivison, Y. Wang, J. Liu, Z. Wu, V. Pyatkin, N. Lambert, N. A. Smith, Y. Choi, andH. Hajishirzi. Unpacking DPO and PPO: Disentangling Best Practices for Learning fromPreference Feedback. arXiv preprint arXiv:2406.09279, 2024. URL https://arxiv.org/abs/2406.09279.
S. Joseph, L. Chen, J. Trienes, H. Göke, M. Coers, W. Xu, B. Wallace, and J. J. Li. FactPICO:Factuality Evaluation for Plain Language Summarization of Medical Evidence. In L.-W. Ku,A. Martins, and V. Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Associationfor Computational Linguistics (Volume 1: Long Papers), pages 8437–8464, Bangkok,Thailand, Aug. 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.acllong.459. URL https://aclanthology.org/2024.acl-long.459/. DOI: https://doi.org/10.18653/v1/2024.acl-long.459
Z. Kenton, N. Y. Siegel, J. Kramar, J. Brown-Cohen, S. Albanie, J. Bulian, R. Agarwal,D. Lindner, Y. Tang, N. Goodman, et al. On scalable oversight with weak LLMs judgingstrong LLMs. In The Thirty-eighth Annual Conference on Neural Information ProcessingSystems, 2024. URL https://openreview.net/forum?id=O1fp9nVraj.
F. Khanzada. Conformity Assessment: Relevance of Quality in the Age of Industry 4.0. InHandbook of Quality System, Accreditation and Conformity Assessment, pages 1–28. Springer,2024. URL https://link.springer.com/referenceworkentry/10.1007/978-981-99-4637-2_1-1. DOI: https://doi.org/10.1007/978-981-99-4637-2_1-1
R. F. Kizilcec. How Much Information? Effects of Transparency on Trust in an AlgorithmicInterface. In Proceedings of the 2016 CHI Conference on Human Factors in ComputingSystems, pages 2390–2395, 2016. URL https://dl.acm.org/doi/abs/10.1145/2858036.2858402. DOI: https://doi.org/10.1145/2858036.2858402
T. Kuhn. The Nature of Scientific Revolutions. Chicago: University of Chicago, 197(0), 1970.
P. M. La Marca, D. Redfield, and P. C. Winter. State Standards and State Assessment Systems:A Guide to Alignment. Series on Standards and Assessments. Non-Journal, 2000. URLhttps://files.eric.ed.gov/fulltext/ED466497.pdf.
H. Lee, S. Phatale, H. Mansoor, T. Mesnard, J. Ferret, K. R. Lu, C. Bishop, E. Hall, V. Carbune,A. Rastogi, et al. RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedbackwith AI Feedback. In Forty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=uydQ2W41KO.
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t.Yih, T. Rocktäschel, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLPTasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020. URLhttps://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html.
Z. Li, H. Zhu, Z. Lu, and M. Yin. Synthetic data generation with large language models fortext classification: Potential and limitations. In H. Bouamor, J. Pino, and K. Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,pages 10443–10461, Singapore, Dec. 2023. Association for Computational Linguistics.doi:10.18653/v1/2023.emnlp-main.647. URL https://aclanthology.org/2023.emnlp-main.647/. DOI: https://doi.org/10.18653/v1/2023.emnlp-main.647
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y. Zhang, D. Narayanan,Y. Wu, A. Kumar, et al. Holistic Evaluation of Language Models. Transactions on MachineLearning Research, 2023. URL https://openreview.net/forum?id=iO4LZibEqW.
D. Liu and V. Demberg. ChatGPT vs human-authored text: Insights into controllable textsummarization and sentence style transfer. In V. Padmakumar, G. Vallejo, and Y. Fu, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics(Volume 4: Student Research Workshop), pages 1–18, Toronto, Canada, July 2023. Associationfor Computational Linguistics. doi:10.18653/v1/2023.acl-srw.1. URL https://aclanthology.org/2023.acl-srw.1/. DOI: https://doi.org/10.18653/v1/2023.acl-srw.1
J. Liu, K. Marriott, T. Dwyer, and G. Tack. Increasing user trust in optimisation throughfeedback and interaction. ACM Transactions on Computer-Human Interaction, 29(5):1–34,2023. URL https://dl.acm.org/doi/pdf/10.1145/3503461. DOI: https://doi.org/10.1145/3503461
A. M. Bran, S. Cox, O. Schilter, C. Baldassari, A. D. White, and P. Schwaller. Augmentinglarge language models with chemistry tools. Nature Machine Intelligence, pages 1–11, 2024.URL https://www.nature.com/articles/s42256-024-00832-8.
A. Malik, S. Mayhew, C. Piech, and K. Bicknell. From tarzan to Tolkien: Controllingthe language proficiency level of LLMs for content generation. In L.-W. Ku, A. Martins,and V. Srikumar, editors, Findings of the Association for Computational Linguistics: ACL2024, pages 15670–15693, Bangkok, Thailand, Aug. 2024. Association for ComputationalLinguistics. doi:10.18653/v1/2024.findings-acl.926. URL https://aclanthology.org/2024.findings-acl.926/. DOI: https://doi.org/10.18653/v1/2024.findings-acl.926
D. Manheim, S. Martin, M. Bailey, M. Samin, and R. Greutzmacher. The Necessity of AIAudit Standards Boards. arXiv preprint arXiv:2404.13060, 2024. URL https://arxiv.org/pdf/2404.13060v1. DOI: https://doi.org/10.1007/s00146-025-02320-y
McKinsey & Company. The State of AI in Early 2024: Gen AI Adoption Spikes and Starts toGenerate Value. 2024. URL https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai. Accessed: 2025-01-22.
B. Meskó and E. J. Topol. The imperative for regulatory oversight of large language models(or generative AI) in healthcare. NPJ Digital Medicine, 6(1):120, 2023. URL https://www.nature.com/articles/s41746-023-00873-0. DOI: https://doi.org/10.1038/s41746-023-00873-0
L. J. V. Miranda, Y. Wang, Y. Elazar, S. Kumar, V. Pyatkin, F. Brahman, N. A. Smith,H. Hajishirzi, and P. Dasigi. Hybrid Preferences: Learning to Route Instances for Human vs.AI Feedback. arXiv preprint arXiv:2410.19133, 2024. URL https://arxiv.org/abs/2410.19133.
S. Mishra, D. Khashabi, C. Baral, Y. Choi, and H. Hajishirzi. Reframing Instructional Promptsto GPTk‘s Language. In S. Muresan, P. Nakov, and A. Villavicencio, editors, Findings of theAssociation for Computational Linguistics: ACL 2022, pages 589–612, Dublin, Ireland, May2022. Association for Computational Linguistics. doi:10.18653/v1/2022.findings-acl.50. URLhttps://aclanthology.org/2022.findings-acl.50/. DOI: https://doi.org/10.18653/v1/2022.findings-acl.50
MLCommons. AILuminate: A Collaborative, Transparent Approach to Safer AI, 2025. URLhttps://mlcommons.org/ailuminate/. Accessed: 2025-01-21.
J. Mökander, J. Schuett, H. R. Kirk, and L. Floridi. Auditing Large Language Models: AThree-Layered Approach. AI and Ethics, pages 1–31, 2023. URL https://link.springer.com/article/10.1007/s43681-023-00289-2. DOI: https://doi.org/10.2139/ssrn.4361607
S. Y. Muluk. Enhancing Musculoskeletal Injection Safety: Evaluating Checklists Generatedby Artificial Intelligence and Revising the Preformed Checklist. Cureus, 16(5):e59708, 2024.URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11150897/.
National Science Foundation. Science and engineering indicators 2018, 2018. URL https://www.nsf.gov/statistics/2018/nsb20181/. Accessed: 2025-01-23.
OpenAI. GPT-4V System Card, 2023. URL https://openai.com/index/gpt-4v-system-card/. Accessed: 2025-01-14.
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal,K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.
A. Papenmeier, D. Kern, G. Englebienne, and C. Seifert. It’s Complicated: The Relationshipbetween User Trust, Model Accuracy and Explanations in AI. ACM Transactions on Computer-Human Interaction (TOCHI), 29(4):1–33, 2022. URL https://dl.acm.org/doi/full/10.1145/3495013. DOI: https://doi.org/10.1145/3495013
E. Posner. Sequence as Explanation: The International Politics of Accounting Standards.Review of International Political Economy, 17(4):639–664, 2010. URL https://scholar.google.com/scholar?output=instlink&q=info:_GvPJNuJ0xkJ:scholar.google.com/&hl=en&as_sdt=0,5&scillfp=7528166911765330717&oi=lle. DOI: https://doi.org/10.1080/09692291003723748
H. Pouget. The EU’s AI Act Is Barreling Toward AI Standards That Do Not Exist. Lawfare,2023. URL https://www.lawfaremedia.org/article/eus-ai-act-barreling-toward-ai-standards-do-not-exist. Accessed: 2025-01-24.
H. Pouget and R. Zuhdi. AI and Product Safety Standards under the EU AI Act, 2024. URLhttps://carnegieendowment.org/research/2024/03/ai-and-product-safety-standards-under-the-eu-ai-act?lang=en¢er=middle-east. Accessed:2025-01-07.
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct PreferenceOptimization: Your Language Model is Secretly a Reward Model. Advances in NeuralInformation Processing Systems, 36, 2024. URL https://dl.acm.org/doi/abs/10.5555/3666122.3668460.
O. Ram, Y. Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton-Brown, and Y. Shoham.In-Context Retrieval-Augmented Language Models. Transactions of the Association forComputational Linguistics, 11:1316–1331, 2023. doi:10.1162/tacl_a_00605. URL https://aclanthology.org/2023.tacl-1.75/. DOI: https://doi.org/10.1162/tacl_a_00605
P. Regulation. Regulation (EU) 2016/679 of the European Parliament and of the Council.Regulation (EU), 679:2016, 2016.
J. Riegelsberger, M. A. Sasse, and J. D. McCarthy. The Mechanics of Trust: A Frameworkfor Research and Design. International Journal of Human-Computer Studies, 62(3):381–422,2005. URL https://www.sciencedirect.com/science/article/pii/S1071581905000121. DOI: https://doi.org/10.1016/j.ijhcs.2005.01.001
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-Resolution ImageSynthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition, pages 10684–10695, 2022. URL https://www.computer.org/csdl/proceedings-article/cvpr/2022/694600k0674/1H1iFsO7Zuw.
D. R. Sadler. Academic achievement standards and quality assurance. Quality in HigherEducation, 23(2):81–99, 2017. URL https://www.tandfonline.com/doi/pdf/10.1080/13538322.2017.1356614. DOI: https://doi.org/10.1080/13538322.2017.1356614
M. Sallam, M. Barakat, M. Sallam, et al. A Preliminary Checklist (METRICS) to Standardizethe Design and Reporting of Studies on Generative Artificial Intelligence–Based Modelsin Health Care Education and Practice: Development Study Involving a Literature Review.Interactive Journal of Medical Research, 13(1):e54704, 2024. URL https://pubmed.ncbi.nlm.nih.gov/38276872/. DOI: https://doi.org/10.2196/54704
F. Sanmarchi, A. Bucci, A. G. Nuzzolese, G. Carullo, F. Toscano, N. Nante, and D. Golinelli.A step-by-step researcher’s guide to the use of an AI-based transformer in epidemiology:an exploratory analysis of ChatGPT using the STROBE checklist for observational studies.Journal of Public Health, 32(9):1761–1796, 2024. URL https://link.springer.com/article/10.1007/s10389-023-01936-y. DOI: https://doi.org/10.1007/s10389-023-01936-y
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer,N. Cancedda, and T. Scialom. Toolformer: Language Models Can Teach Themselves to UseTools. Advances in Neural Information Processing Systems, 36:68539–68551, 2023. URLhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/d842425e4bf79ba039352da0f658a906-Abstract-Conference.html.
P. Schmidt, F. Biessmann, and T. Teubner. Transparency and trust in artificial intelligencesystems. Journal of Decision Systems, 29(4):260–278, 2020. URL https://www.tandfonline.com/doi/full/10.1080/12460125.2020.1819094. DOI: https://doi.org/10.1080/12460125.2020.1819094
T. Shin, Y. Razeghi, R. L. Logan IV, E. Wallace, and S. Singh. AutoPrompt: ElicitingKnowledge from Language Models with Automatically Generated Prompts. In B. Webber,T. Cohn, Y. He, and Y. Liu, editors, Proceedings of the 2020 Conference on EmpiricalMethods in Natural Language Processing (EMNLP), pages 4222–4235, Online, Nov. 2020.Association for Computational Linguistics. doi:10.18653/v1/2020.emnlp-main.346. URLhttps://aclanthology.org/2020.emnlp-main.346/. DOI: https://doi.org/10.18653/v1/2020.emnlp-main.346
M. L. Siddiq, B. Casey, and J. Santos. A lightweight framework for high-quality codegeneration. arXiv preprint arXiv:2307.08220, 2023. URL https://arxiv.org/pdf/2307.08220.
C. Song and V. Shmatikov. Auditing Data Provenance in Text-Generation Models. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery &Data Mining, pages 196–206, 2019. URL https://dl.acm.org/doi/abs/10.1145/3292500.3330885. DOI: https://doi.org/10.1145/3292500.3330885
A. Srivastava, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. R. Brown, A. Santoro,A. Gupta, A. Garriga-Alonso, et al. Beyond the Imitation Game: Quantifying and Extrapolatingthe Capabilities of Language Models. Transactions on Machine Learning Research, 2023.URL https://openreview.net/forum?id=uyTL5Bvosj.
I. Stoica, M. Zaharia, J. Gonzalez, K. Goldberg, H. Zhang, A. Angelopoulos, S. G. Patil,L. Chen, W.-L. Chiang, and J. Q. Davis. Specifications: The missing link to making thedevelopment of LLM systems an engineering discipline. arXiv preprint arXiv:2412.05299,2024. URL https://arxiv.org/abs/2412.05299.
D. Tapscott and A. Caston. Paradigm Shift: The New Promise of Information Technology.Economic Development Journal of Canada, pages 62–66, 1994.
C. Teo, M. Abdollahzadeh, and N.-M. M. Cheung. On Measuring Fairness in GenerativeModels. Advances in Neural Information Processing Systems, 36, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/220165f9c7f51163b73c8c7fff578b4e-Abstract-Conference.html.
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra,P. Bhargava, S. Bhosale, et al. Llama 2: Open Foundation and Fine-Tuned Chat Modelss.arXiv preprint arXiv:2307.09288, 2023. URL https://arxiv.org/abs/2307.09288.
E. Von Elm, D. G. Altman, M. Egger, S. J. Pocock, P. C. Gøtzsche, and J. P. Vandenbroucke.The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement:guidelines for reporting observational studies. The Lancet, 370(9596):1453–1457, 2007.URL https://www.thelancet.com/pdfs/journals/lancet/PIIS0140-6736(07)61602-X.pdf. DOI: https://doi.org/10.1016/S0140-6736(07)61602-X
H. Weber and H. Ehrig. Specification of modular systems. IEEE Transactions on SoftwareEngineering, (7):784–798, 1986. URL https://www.computer.org/csdl/journal/ts/1986/07/06312979/13rRUyuNsyH. DOI: https://doi.org/10.1109/TSE.1986.6312979
J. Wei, M. Bosma, V. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le.Finetuned language models are zero-shot learners. In International Conference on LearningRepresentations, 2022.
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chainof-Thought Prompting Elicits Reasoning in Large Language Models. Advances in NeuralInformation Processing Systems, 35:24824–24837, 2022. URL https://openreview.net/forum?id=_VjQlMeSB_J.
J. Ye, J. Gao, Q. Li, H. Xu, J. Feng, Z. Wu, T. Yu, and L. Kong. ZeroGen: EfficientZero-shot Learning via Dataset Generation. In Y. Goldberg, Z. Kozareva, and Y. Zhang,editors, Proceedings of the 2022 Conference on Empirical Methods in Natural LanguageProcessing, pages 11653–11669, Abu Dhabi, United Arab Emirates, Dec. 2022. Associationfor Computational Linguistics. doi:10.18653/v1/2022.emnlp-main.801. URL https://aclanthology.org/2022.emnlp-main.801/. DOI: https://doi.org/10.18653/v1/2022.emnlp-main.801
J. Zhang, A. Elgohary, A. Magooda, D. Khashabi, and B. Van Durme. Controllable SafetyAlignment: Inference-Time Adaptation to Diverse Safety Requirements. arXiv preprintarXiv:2410.08968, 2024. URL https://arxiv.org/pdf/2410.08968.
L. Zhang, A. Rao, and M. Agrawala. Adding Conditional Control to Text-to-Image DiffusionModels. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages3836–3847, 2023. URL https://ieeexplore.ieee.org/abstract/document/10377881/.
C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu, L. YU, S. Zhang,G. Ghosh, M. Lewis, L. Zettlemoyer, and O. Levy. LIMA: Less Is More for Alignment. InA. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances inNeural Information Processing Systems, volume 36, pages 55006–55021. Curran Associates,Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ac662d74829e4407ce1d126477f4a03a-Paper-Conference.pdf.
W. Zhou, Y. E. Jiang, E. Wilcox, R. Cotterell, and M. Sachan. Controlled text generation withnatural language instructions. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, andJ. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning,volume 202 of Proceedings of Machine Learning Research, pages 42602–42613. PMLR,23–29 Jul 2023. URL https://proceedings.mlr.press/v202/zhou23g.html.
L. Zhu, L. Yang, C. Li, S. Hu, L. Liu, and B. Yin. LegiLM: A Fine-Tuned Legal LanguageModel for Data Compliance. arXiv preprint arXiv:2409.13721, 2024. URL https://arxiv.org/pdf/2409.13721.
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano,and G. Irving. Fine-Tuning Language Models from Human Preferences. arXiv preprintarXiv:1909.08593, 2019. URL https://arxiv.org/abs/1909.08593.
M. Zoubi, S. T.y.s.s, E. Rosas, and M. Grabmair. PrivaT5: A generative language model forprivacy policies. In I. Habernal, S. Ghanavati, A. Ravichander, V. Jain, P. Thaine, T. Igamberdiev,N. Mireshghallah, and O. Feyisetan, editors, Proceedings of the Fifth Workshop onPrivacy in Natural Language Processing, pages 159–169, Bangkok, Thailand, Aug. 2024.Association for Computational Linguistics. URL https://aclanthology.org/2024.privatenlp-1.16/. DOI: https://doi.org/10.18653/v1/2024.privatenlp-1.16
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2025 Joseph Marvin Imperial, Matthew D. Jones, Harish Tayyar Madabushi

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.

