
From Hard Refusals to Safe-Completions: Toward Output-Centric Safety Training
DOI:
https://doi.org/10.70777/si.v2i6.15625Keywords:
Refusal training , Dual-use prompts , AI Safety policy, Reinforcement Learning (RL), ai Harm severity, ai Biorisk, ai Human safety evaluation, ai content policyAbstract
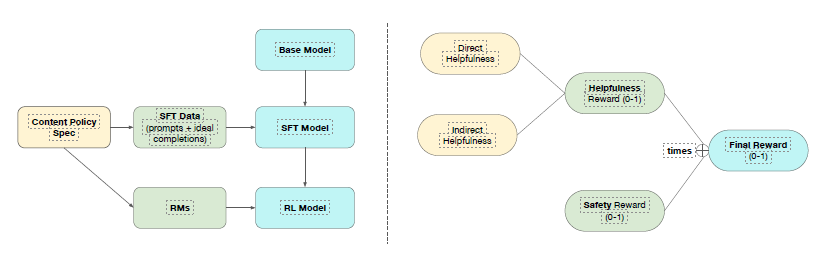
Large Language Models used in ChatGPT have traditionally been trained to learn a refusal boundary: depending on the user’s intent, the model is taught to either fully comply or out-right refuse. While this is a strong mitigation for explicitly malicious prompts, focusing safety training on refusals can lead to brittleness for prompts with obscured user intent. Binary refusal boundaries are especially ill-suited for dual-use cases (such as biology or cybersecurity), where a user request can be answered safely at a high level, but in some cases can lead to malicious uplift if sufficiently detailed or actionable. As an alternative, we propose safe-completions: a safety-training approach that centers on the safety of the assistant’s output, rather than a bi-nary classification of the user’s intent. Safe-completions seek to maximize helpfulness within the safety policy’s constraints. We incorporated this approach into GPT-5 and find that across both production comparisons and internally controlled experiments, safe-completion training improves safety (especially on dual-use prompts), reduces the severity of residual safety failures, and substantially increases model helpfulness.
References
An, B., Zhu, S., Zhang, R., Panaitescu-Liess, M.-A., Xu, Y., and Huang, F. Auto-matic pseudo-harmful prompt generation for evaluating false refusals in large language models. Conference on Language Modeling (2024).
Andriushchenko, M., Croce, F., and Flammarion, N. Jailbreaking leading safety-aligned LLMs with simple adaptive attacks. arXiv preprint arXiv:2404.02151 (2024).
Anil, C., Grosse, R. B., and Duvenaud, D. Many-shot jailbreaking. In Advances in Neural Information Processing Systems (2024).
Anthropic. Claude 3.7 sonnet system card. Tech. rep., Feb. 2025. Accessed: 2025-08-04.
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., Johnston, S., Kravec, S., Lovitt, L., Nanda, N., Olsson, C., Amodei, D., Brown, T., Clark, J., McCandlish, S., Olah, C., Mann, B., and Kaplan, J. Training a helpful and harmless assistant with reinforcement learning from human feedback. https: //arxiv.org/abs/2204.05862, Apr. 2022. arXiv:2204.05862 [cs.CL]; accessed 2025-08-06.
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., Chen, C., Olsson, C., Olah, C., Her-nandez, D., Drain, D., Ganguli, D., Li, D., Tran-Johnson, E., Perez, E., Kerr, J., Mueller, J., Ladish, J., Landau, J., Ndousse, K., Lukosiute, K., Lovitt, L., Sellitto, M., Elhage, N., Schiefer, N., Mercado, N., DasSarma, N., Lasenby, R., Larson, R., Ringer, S., Johnston, S., Kravec, S., El-Showk, S., Fort, S., Lanham, T., Telleen-Lawton, T., Conerly, T., Henighan, T., Hume, T., Bowman, S. R., Hatfield-Dodds, Z., Mann, B., Amodei, D., Joseph, N., McCandlish, S., Brown, T., and Kaplan, J. Constitutional AI: Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073 (2022).
Bianchi, F., Suzgun, M., Attanasio, G., Röttger, P., Jurafsky, D., Hashimoto, T., and Zou, J. Safety-tuned LLaMAs: Lessons from improving the safety of large language models that follow instructions. arXiv preprint arXiv:2309.07875 (2023).
Dai, J., Pan, X., Sun, R., Ji, J., Xu, X., Liu, M., Wang, Y., and Yang, Y. Safe RLHF: Safe reinforcement learning from human feedback. arXiv preprint arXiv:2310.12773 (2023).
Guan, M. Y., Joglekar, M., Wallace, E., Jain, S., Barak, B., Helyar, A., Dias, R., Vallone, A., Ren, H., Wei, J., et al. Deliberative alignment: Reasoning enables safer language models. arXiv preprint arXiv:2412.16339 (2024).
Mu, T., Helyar, A., Heidecke, J., Achiam, J., Vallone, A., Kivlichan, I., Lin, M., Beutel, A., Schulman, J., and Weng, L. Rule based rewards for language model safety. Advances in Neural Information Processing Systems 37 (2024), 108877–108901.
OpenAI. Building an early warning system for LLMaided biological threat creation. https://openai.com/index/ building-an-early-warning-system-for-llm-aided-biological-threat-creation, January 2024. Accessed: 2025-08-05.
OpenAI. GPT-4o system card. arXiv preprint arXiv:2410.21276 (2024).
OpenAI. OpenAI model specification (model spec). https://model-spec.openai.com/, Feb. 2025. CC0 1.0 public domain; accessed 2025-07-30.
OpenAI. OpenAI o3 and o4-mini system card. System card, OpenAI, Apr. 2025.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (2022).
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems 36 (2023), 53728–53741.
Röttger, P., Kirk, H. R., Vidgen, B., Attanasio, G., Bianchi, F., and Hovy, D. XStest: A test suite for identifying exaggerated safety behaviours in large language models. arXiv preprint arXiv:2308.01263 (2023).
Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., and Hashimoto, T. Whose opinions do language models reflect?, 2023.
Shi, C., Wang, X., Ge, Q., Gao, S., Yang, X., Gui, T., Zhang, Q., Huang, X., Zhao, X., and Lin, D. Navigating the OverKill in large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Bangkok, Thailand, Aug. 2024), L.-W. Ku, A. Martins, and V. Srikumar, Eds., Association for Computational Linguistics, pp. 4602–4614.
Varshney, N., Dolin, P., Seth, A., and Baral, C. The art of defending: A systematic evaluation and analysis of llm defense strategies on safety and over-defensiveness. Findings of the Association for Computational Linguistics (2024).
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043 (2023).
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2025 Yuan Yuan, Tina Sriskandarajah, Anna-Luisa Brakman, Alec Helyar, Alex Beutel, Andrea Vallone, Saachi Jain

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.

