
OpenAI: Toward Mechanistic Interpretability (MI)
DOI:
https://doi.org/10.70777/si.v2i6.16545Keywords:
sparse encoding, distillation, mixture of experts, llm, mechanistic interpretability, explainable aiAbstract
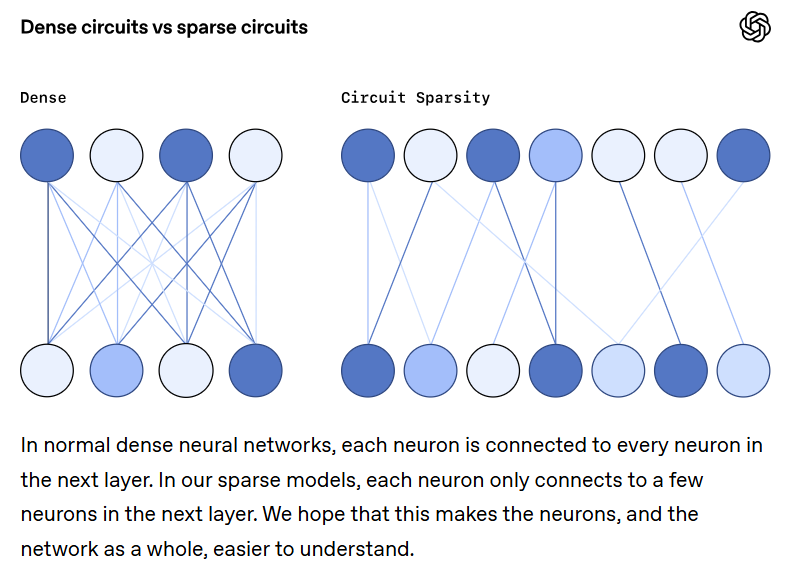
OpenAI just released a report on experimenting with sparsely-connected models to see if they are more interpretable than densely-connected models. They are, and the OpenAI team found they could identify the exact circuit computing a general function of interest. We give a short summary of their work with links to their blog post and article, and compare with Stephen Wolfram's 2024 investigation of the smallest net that could compute a given simple function.
References
https://openai.com/index/understanding-neural-networks-through-sparse-circuits/
Gao et al., Weight-sparse transformers have interpretable circuits https://cdn.openai.com/pdf/41df8f28-d4ef-43e9-aed2-823f9393e470/circuit-sparsity-paper.pdf
Wolfram, What’s Really Going On in Machine Learning? Some Minimal Models https://writings.stephenwolfram.com/2024/08/whats-really-going-on-in-machine-learning-some-minimal-models/ DOI: https://doi.org/10.31855/e0e30753-e3f
Wolfram, What If We Had Bigger Brains? Imagining Minds beyond Ours https://writings.stephenwolfram.com/2025/05/what-if-we-had-bigger-brains-imagining-minds-beyond-ours/
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Kris Carlson

This work is licensed under a Creative Commons Attribution 4.0 International License.

