
A Grading Rubric for AI Safety Frameworks
DOI:
https://doi.org/10.70777/si.v2i5.16331Keywords:
AI safety frameworks, AI Risk management, Frontier AI systems, Catastrophic risks, AI Compliance, artificial general intelligence agi, superintelligence, ai governanceAbstract
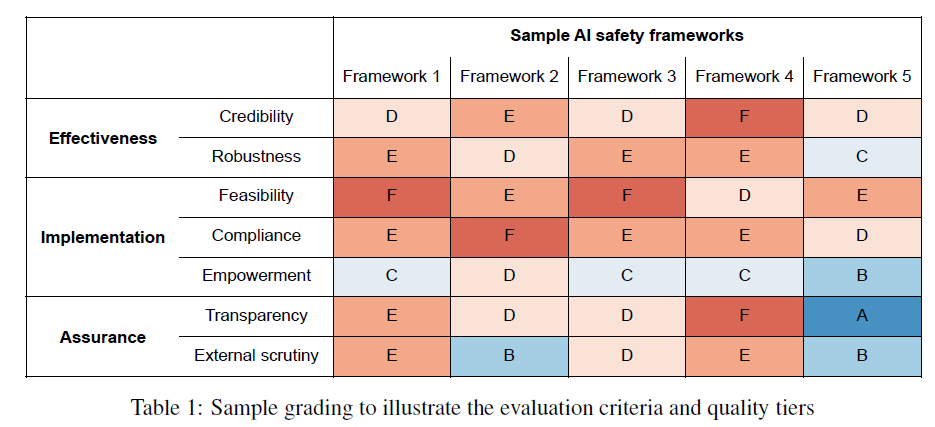
Over the past year, artificial intelligence (AI) companies have been increasingly adopting AI safety frameworks. These frameworks outline how companies intend to keep the potential risks associated with developing and deploying frontier AI systems to an acceptable level. Major players like Anthropic, OpenAI, and Google DeepMind have already published their frameworks, while another 13 companies have signaled their intent to release similar frameworks by February 2025. Given their central role in AI companies’ efforts to identify and address unacceptable risks from their systems, AI safety frameworks warrant significant scrutiny. To enable governments, academia, and civil society to pass judgment on these frameworks, this paper proposes a grading rubric. The rubric consists of seven evaluation criteria and 21 indicators that concretize the criteria. Each criterion can be graded on a scale from A (gold standard) to F (substandard). The paper also suggests three methods for applying the rubric: surveys, Delphi studies, and audits. The purpose of the grading rubric is to enable nuanced comparisons between frameworks, identify potential areas of improvement, and promote a race to the top in responsible AI development.
References
J. Alaga and J. Schuett. Coordinated pausing: An evaluation-based coordination scheme for frontier AI developers. arXiv preprint arXiv:2310.00374, 2023.
B. Anderson-Samways, S. Ee, J. O’Brien, M. Buhl, and Z. Williams. Responsible scaling: Comparing government guidance and company policy. Institute for AI Policy and Strategy, https://www.iaps.ai/research/responsible-scaling, 2024.
Anthropic. Responsible Scaling Policy. https://www.anthropic.com/news/anthropic s-responsible-scaling-policy, 2023.
Anthropic. Reflections on our Responsible Scaling Policy. https://www.anthropic.com/ news/reflections-on-our-responsible-scaling-policy, 2024.
W. Aspinall. A route to more tractable expert advice. Nature, 463:294–295, 2010. https: //doi.org/10.1038/463294a.
T. Aven. On the meaning of a black swan in a risk context. Safety Science, 57:44–51, 2013. https://doi.org/10.1016/j.ssci.2013.01.016.
T. Aven. Risk assessment and risk management: Review of recent advances on their foundation. European Journal of Operational Research, 253(1):1–13, 2016. https://doi.org/10.101 6/j.ejor.2015.12.023.
U. Bantleon, A. d’Arcy, M. Eulerich, A. Hucke, B. Pedell, and N. V. Ratzinger-Sakel. Coordination challenges in implementing the Three Lines of Defense model. International Journal of Auditing, 25(1):59–74, 2021. https://doi.org/10.1111/ijau.12201.
P. Cihon, M. J. Kleinaltenkamp, J. Schuett, and S. D. Baum. AI certification: Advancing ethical practice by reducing information asymmetries. IEEE Transactions on Technology and Society, 2(4):200–209, 2021. https://doi.org/10.1109/TTS.2021.3077595.
R. M. Cooke and L. H. J. Goossens. Expert judgement elicitation for risk assessments of critical infrastructures. Journal of Risk Research, 7(6):643–656, 2004. https://doi.org/10.1080/ 1366987042000192237.
O. Cotton-Barratt, M. Daniel, and A. Sandberg. Defence in depth against human extinction: Prevention, response, resilience, and why they all matter. Global Policy, 11(3):271–282, 2020. https://doi.org/10.1111/1758-5899.12786.
H. Davies and M. Zhivitskaya. Three Lines of Defence: A robust organising framework, or just lines in the sand? Global Policy, 9:34–42, 2018. https://doi.org/10.1111/1758-5899. 12568.
L. Decaux and G. Sarens. Implementing combined assurance: Insights from multiple case studies. Managerial Auditing Journal, 30(1):56–79, 2015. https://doi.org/10.1108/MA J-08-2014-1074.
A. Dragan, K. King, Helen, and A. Dafoe. Introducing the Frontier Safety Framework. Google DeepMind, https://deepmind.google/discover/blog/introducing-the-frontie r-safety-framework, 2024.
DSIT. Emerging Processes for Frontier AI Safety. https://www.gov.uk/government/pu blications/emerging-processes-for-frontier-ai-safety, 2023.
DSIT. Frontier AI Safety Commitments, AI Seoul Summit 2024. https://www.gov.uk/gov ernment/publications/frontier-ai-safety-commitments-ai-seoul-summit-2 024, 2024.
S. Ee, J. O’Brien, Z. Williams, A. El-Dakhakhni, M. Aird, and A. Lintz. Adapting cybersecurity frameworks to manage frontier AI risks: A defense-in-depth approach. arXiv preprint arXiv:2408.07933, 2024.
K. N. Fleming and F. A. Silady. A risk informed defense-in-depth framework for existing and advanced reactors. Reliability Engineering & System Safety, 78(3):205–225, 2002. https: //doi.org/10.1016/S0951-8320(02)00153-9.
R. B. Gilbert, M. Habibi, and F. Nadim. Accounting for unknown unknowns in managing multi-hazard risks. In P. Gardoni and J. M. LaFave, editors, Multi-hazard approaches to civil infrastructure engineering, pages 383–412. Springer, 2016. https://doi.org/10.1007/97 8-3-319-29713-2_18.
J.-E. Holmberg. Defense-in-depth. In N. Moller, S. Ove Hansson, J.-E. Holmberg, and C. Rollenhagen, editors, Handbook of safety principles, pages 42–62. Wiley, 2017. https: //doi.org/10.1002/9781119443070.ch4.
C.-C. Hsu and B. A. Sandford. The Delphi technique: Making sense of consensus. Practical Assessment, Research, and Evaluation, 12(1), 2007. https://doi.org/10.7275/PDZ9-TH9 0.
S. C. Huibers. Combined assurance: One language, one voice, one view. IIA Research Foundation, Global Internal Audit Common Body of Knowledge, https://perma.cc/D7Y M-9GSY, 2015.
Institute of Internal Auditors. IIA position paper: The Three Lines of Defense in effective risk management and control. https://perma.cc/NQM2-DD7V, 2013.
Institute of Internal Auditors. The IIA’s Three Lines Model: An update of the Three Lines of Defense. https://perma.cc/GAB5-DMN3, 2020.
ISO 31000. Risk management—Guidelines. https://www.iso.org/standard/65694.h tml, 2018.
ISO/IEC 23894. Information technology — Artificial intelligence — Guidance on risk management. https://www.iso.org/standard/77304.html, 2023.
C. Kirchsteiger. On the use of probabilistic and deterministic methods in risk analysis. Journal of Loss Prevention in the Process Industries, 12(5):399–419, 1999. https://doi.org/10.1 016/S0950-4230(99)00012-1.
L. Koessler, J. Schuett, and M. Anderljung. Risk thresholds for frontier AI. arXiv preprint arXiv:2406.14713, 2024.
N. Kolt. Algorithmic black swans. Washington University Law Review, 101, 2024. https: //ssrn.com/abstract=4370566.
N. Kolt, M. Anderljung, J. Barnhart, A. Brass, K. Esvelt, G. K. Hadfield, L. Heim, M. Rodriguez, J. B. Sandbrink, and T. Woodside. Responsible reporting for frontier AI development. arXiv preprint arXiv:2404.02675, 2024.
J. Larouzee and J.-C. Le Coze. Good and bad reasons: The Swiss cheese model and its critics. Safety Science, 126:104660, 2020. https://doi.org/10.1016/j.ssci.2020.104660.
W. Li and P. Kamal. Integrated aviation security for defense-in-depth of next generation air transportation system. In IEEE International Conference on Technologies for Homeland Security, pages 136–142, 2011. https://doi.org/10.1109/THS.2011.6107860.
Magic. AGI Readiness Policy Version 1.0. https://magic.dev/agi-readiness-policy, 2024.
METR. Key components of an RSP. https://metr.org/rsp-key-components, 2023.
METR. Responsible Scaling Policies (RSPs). https://metr.org/blog/2023-09-26-rsp, 2023.
METR. Common elements of frontier AI safety policies. https://metr.org/blog/2024-0 8-29-common-elements-of-frontier-ai-safety-policies, 2024.
J. Mokander, J. Schuett, H. R. Kirk, and L. Floridi. Auditing large language models: A threelayered approach. AI and Ethics, 2023. https://doi.org/10.1007/s43681-023-00289 -2.
S. O hEigeartaigh, Y. Lannquist, A. Marcoci, J. Sevilla, M. A. Ulloa Ruiz, Y. Chaudhary, T. Schreier, Z. Stein-Perlman, and J. L. Ladish. Do companies’ AI safety policies meet government best practice? Leverhulme Centre for the Future of Intelligence, www.lcfi.ac.uk /news-and-events/news/2023/oct/31/ai-safety-policies, 2024.
OpenAI. Preparedness Framework (Beta). https://openai.com/preparedness, 2023.
C. Perrow. Normal accidents: Living with high-risk technologies. Princeton University Press, 2000.
M. Phuong, M. Aitchison, E. Catt, S. Cogan, A. Kaskasoli, V. Krakovna, D. Lindner, M. Rahtz, Y. Assael, S. Hodkinson, H. Howard, T. Lieberum, R. Kumar, M. A. Raad, A. Webson, L. Ho, S. Lin, S. Farquhar, M. Hutter, G. Deletang, A. Ruoss, S. El-Sayed, S. Brown, A. Dragan, R. Shah, A. Dafoe, and T. Shevlane. Evaluating frontier models for dangerous capabilities. arXiv preprint arXiv:2403.13793, 2024.
J. Reason. The contribution of latent human failures to the breakdown of complex systems. Philosophical Transactions of the Royal Society B, 327(1241):475–484, 1990. https://doi. org/10.1098/rstb.1990.0090.
J. Reason. Human error. Cambridge University Press, 1990. https://doi.org/10.1017/ CBO9781139062367.
G. M. Richardson. Deterministic versus probabilistic risk assessment: Strengths and weaknesses in a regulatory context. Human and Ecological Risk Assessment: An International Journal, 2(1):44–54, 1996. https://doi.org/10.1080/10807039.1996.10387459.
B. Robinson and J. Ginns. Transforming risk governance at frontier AI companies. The Centre for Long-Term Resilience, https://www.longtermresilience.org/post/transformi ng-risk-governance-at-frontier-ai-companies, 2024.
SaferAI. Is OpenAI’s Preparedness Framework better than its competitors’ Responsible Scaling Policies? A comparative analysis. https://www.safer-ai.org/post/is-openais-pre paredness-framework-better-than-its-competitors-responsible-scaling-p olicies-a-comparative-analysis, 2024.
J. Schuett. Three lines of defense against risks from AI. AI & Society, 2023. https: //doi.org/10.1007/s00146-023-01811-0.
J. Schuett, M. Anderljung, A. Carlier, L. Koessler, and B. Garfinkel. From principles to rules: A regulatory approach for frontier AI. arXiv preprint arXiv:2407.07300, 2024.
J. Schuett, N. Dreksler, M. Anderljung, D. McCaffary, L. Heim, E. Bluemke, and B. Garfinkel. Towards best practices in AGI safety and governance: A survey of expert opinion. arXiv preprint arXiv:2305.07153, 2023.
T. Shevlane, S. Farquhar, B. Garfinkel, M. Phuong, J. Whittlestone, J. Leung, D. Kokotajlo, N. Marchal, M. Anderljung, N. Kolt, L. Ho, D. Siddarth, S. Avin, W. Hawkins, B. Kim, I. Gabriel, V. Bolina, J. Clark, Y. Bengio, P. Christiano, and A. Dafoe. Model evaluation for extreme risks. arXiv preprint arXiv:2305.15324, 2023.
M. R. Stytz. Considering defense in depth for software applications. IEEE Security & Privacy Magazine, 2(1):72–75, 2004. https://doi.org/10.1109/MSECP.2004.1264860.
N. N. Taleb. The black swan: The impact of the highly improbable. Random House, 2007.
J. Titus. Scaling AI safely: Can preparedness frameworks pull their weight? Federation of American Scientists, https://fas.org/publication/scaling-ai-safety, 2024.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Jide Alaga, Jonas Schuett, Markus Anderljung

This work is licensed under a Creative Commons Attribution 4.0 International License.

