
DarwinLM: Evolutionary Structured Pruning of Large Language Models
DOI:
https://doi.org/10.70777/si.v2i3.15171Abstract
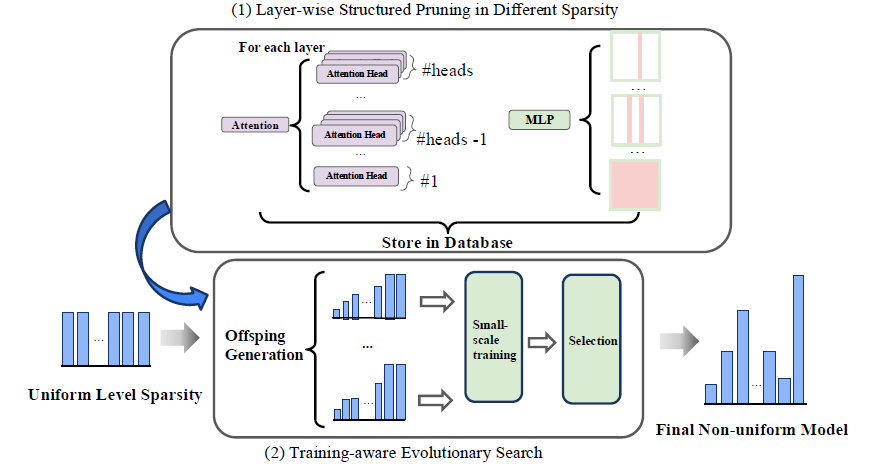
Large Language Models (LLMs) have achieved significant success across various NLP tasks. However, their massive computational costs limit their widespread use, particularly in real-time applications. Structured pruning offers an effective solution by compressing models and directly providing end-to-end speed improvements, regardless of the hardware environment. Meanwhile, different components of the model exhibit varying sensitivities towards pruning, calling for nonuniform model compression. However, a pruning method should not only identify a capable substructure, but also account for post-compression training. To this end, we propose DarwinLM, a method for training-aware structured pruning. DarwinLM builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival. To assess the effect of post-training, we incorporate a lightweight, multistep training process within the offspring population, progressively increasing the number of tokens and eliminating poorly performing models in each selection stage. We validate our method through extensive experiments on Llama- 2-7B, Llama-3.1-8B and Qwen-2.5-14B-Instruct, achieving state-of-the-art performance for structured pruning. For instance, DarwinLM surpasses ShearedLlama while requiring 5× less training data during post-compression training. Code and all weights are released at: https://github.com/ISTDASLab/ DarwinLM.
References
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y.,
Lebr´on, F., and Sanghai, S. Gqa: Training generalized
multi-query transformer models from multi-head checkpoints.
arXiv preprint arXiv:2305.13245, 2023.
An, Y., Zhao, X., Yu, T., Tang, M., andWang, J. Fluctuationbased
adaptive structured pruning for large language models.
In Proceedings of the AAAI Conference on Artificial
Intelligence, 2024.
Bisk, Y., Zellers, R., Gao, J., Choi, Y., et al. Piqa: Reasoning
about physical commonsense in natural language. In Proceedings
of the AAAI conference on artificial intelligence,
volume 34, pp. 7432–7439, 2020.
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins,
M., and Toutanova, K. Boolq: Exploring the surprising
difficulty of natural yes/no questions. In NAACL, 2019.
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A.,
Schoenick, C., and Tafjord, O. Think you have solved
question answering? try arc, the ai2 reasoning challenge.
arXiv preprint arXiv:1803.05457, 2018.
Dettmers, T., Svirschevski, R., Egiazarian, V., Kuznedelev,
D., Frantar, E., Ashkboos, S., Borzunov, A., Hoefler, T.,
and Alistarh, D. Spqr: A sparse-quantized representation
for near-lossless llm weight compression. arXiv preprint
arXiv:2306.03078, 2023.
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle,
A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan,
A., et al. The llama 3 herd of models. arXiv preprint
arXiv:2407.21783, 2024.
Frantar, E. and Alistarh, D. Spdy: Accurate pruning with
speedup guarantees. In International Conference on Machine
Learning, pp. 6726–6743. PMLR, 2022.
Frantar, E. and Alistarh, D. Sparsegpt: Massive language
models can be accurately pruned in one-shot. In International
Conference on Machine Learning, pp. 10323–
PMLR, 2023.
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq:
Accurate post-training quantization for generative pretrained
transformers. arXiv preprint arXiv:2210.17323,
Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi,
A., Foster, C., Golding, L., Hsu, J., Le Noac’h, A., et al.
A framework for few-shot language model evaluation, 12
URL https://zenodo. org/records/10256836, 7.
Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney,
R., Tafjord, O., Jha, A. H., Ivison, H., Magnusson, I.,
Wang, Y., et al. Olmo: Accelerating the science of language
models. arXiv preprint arXiv:2402.00838, 2024.
Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P., and
Roberts, D. A. The unreasonable ineffectiveness of the
deeper layers. arXiv preprint arXiv:2403.17887, 2024.
Gu, Y., Dong, L.,Wei, F., and Huang, M. MiniLLM: Knowledge
distillation of large language models. In The Twelfth
International Conference on Learning Representations,
Hassibi, B. and Stork, D. Second order derivatives for
network pruning: Optimal brain surgeon. Advances in
neural information processing systems, 5, 1992.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika,
M., Song, D., and Steinhardt, J. Measuring massive
multitask language understanding. arXiv preprint
arXiv:2009.03300, 2020.
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge
in a neural network, 2015.
Hsieh, C.-Y., Li, C.-L., Yeh, C.-K., Nakhost, H., Fujii, Y.,
Ratner, A., Krishna, R., Lee, C.-Y., and Pfister, T. Distilling
step-by-step! outperforming larger language models
with less training data and smaller model sizes. arXiv
preprint arXiv:2305.02301, 2023.
Huang, W., Liu, Y., Qin, H., Li, Y., Zhang, S., Liu, X.,
Magno, M., and QI, X. Billm: Pushing the limit of posttraining
quantization for llms. In Forty-first International
Conference on Machine Learning, 2024.
Kim, B.-K., Kim, G., Kim, T.-H., Castells, T., Choi, S.,
Shin, J., and Song, H.-K. Shortened llama: A simple
depth pruning for large language models. arXiv preprint
arXiv:2402.02834, 2024.
Klein, A., Golebiowski, J., Ma, X., Perrone, V., and Archambeau,
C. Structural pruning of large language models via
neural architecture search. In AutoML Conference 2023,
Kurtic, E., Campos, D., Nguyen, T., Frantar, E., Kurtz, M.,
Fineran, B., Goin, M., and Alistarh, D. The optimal bert
surgeon: Scalable and accurate second-order pruning for
large language models. arXiv preprint arXiv:2203.07259,
Kurti´c, E., Frantar, E., and Alistarh, D. Ziplm: Inferenceaware
structured pruning of language models. Advances
in Neural Information Processing Systems, 36, 2024.
Li, S., Ning, X., Wang, L., Liu, T., Shi, X., Yan, S., Dai,
G., Yang, H., and Wang, Y. Evaluating quantized large
language models. In Forty-first International Conference
on Machine Learning, 2024.
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.-M., Wang,
W.-C., Xiao, G., Dang, X., Gan, C., and Han, S. Awq:
Activation-aware weight quantization for on-device llm
compression and acceleration. Proceedings of Machine
Learning and Systems, 6:87–100, 2024.
Liu, C., Zhao, F., Kuang, K., Kang, Y., Jiang, Z., Sun, C.,
andWu, F. Evolving knowledge distillation with large language
models and active learning. In Calzolari, N., Kan,
M.-Y., Hoste, V., Lenci, A., Sakti, S., and Xue, N. (eds.),
Proceedings of the 2024 Joint International Conference
on Computational Linguistics, Language Resources and
Evaluation (LREC-COLING 2024), 2024.
Liu, J., Cui, L., Liu, H., Huang, D., Wang, Y., and Zhang,
Y. Logiqa: A challenge dataset for machine reading
comprehension with logical reasoning. arXiv preprint
arXiv:2007.08124, 2020.
Lozhkov, A., Ben Allal, L., von Werra, L., and
Wolf, T. Fineweb-edu, May 2024. URL
https://huggingface.co/datasets/
HuggingFaceFW/fineweb-edu.
Ma, S., Wang, H., Ma, L., Wang, L., Wang, W., Huang, S.,
Dong, L., Wang, R., Xue, J., and Wei, F. The era of 1-bit
llms: All large language models are in 1.58 bits. arXiv
preprint arXiv:2402.17764, 2024.
Ma, X., Fang, G., and Wang, X. LLM-pruner: On the
structural pruning of large language models. In Thirtyseventh
Conference on Neural Information Processing
Systems, 2023.
Men, X., Xu, M., Zhang, Q., Wang, B., Lin, H., Lu, Y., Han,
X., and Chen,W. Shortgpt: Layers in large language models
are more redundant than you expect. arXiv preprint
arXiv:2403.03853, 2024.
Muralidharan, S., Sreenivas, S. T., Joshi, R., Chochowski,
M., Patwary, M., Shoeybi, M., Catanzaro, B., Kautz,
J., and Molchanov, P. Compact language models via
pruning and knowledge distillation. arXiv preprint
arXiv:2407.14679, 2024.
Qwen, T. Qwen2.5: A party of foundation models, September
blog/qwen2.5/.
Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y.
Winogrande: An adversarial winograd schema challenge
at scale. Communications of the ACM, 64(9):99–106,
Sanh, V. Distilbert, a distilled version of bert: Smaller, faster,
cheaper and lighter. arXiv preprint arXiv:1910.01108,
Sieberling, O., Kuznedelev, D., Kurtic, E., and Alistarh, D.
Evopress: Towards optimal dynamic model compression
via evolutionary search. arXiv preprint arXiv:2410.14649,
Tang, S., Ma, L., Li, H., Sun, M., and Shen, Z. Bi-mamba:
Towards accurate 1-bit state space models. arXiv preprint
arXiv:2411.11843, 2024.
Tao, C., Hou, L., Bai, H., Wei, J., Jiang, X., Liu, Q., Luo,
P., and Wong, N. Structured pruning for efficient generative
pre-trained language models. In Findings of the
Association for Computational Linguistics: ACL 2023,
pp. 10880–10895, 2023.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi,
A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P.,
Bhosale, S., et al. Llama 2: Open foundation and finetuned
chat models. arXiv preprint arXiv:2307.09288,
Wang, H., Ma, S., Dong, L., Huang, S., Wang, H., Ma, L.,
Yang, F., Wang, R., Wu, Y., and Wei, F. Bitnet: Scaling 1-
bit transformers for large language models. arXiv preprint
arXiv:2310.11453, 2023.
Wang, Z., Wohlwend, J., and Lei, T. Structured pruning
of large language models. In Proceedings of the 2020
Conference on Empirical Methods in Natural Language
Processing (EMNLP), pp. 6151–6162, 2020.
Welbl, J., Liu, N. F., and Gardner, M. Crowdsourcing
multiple choice science questions. arXiv preprint
arXiv:1707.06209, 2017.
Xia, M., Gao, T., Zeng, Z., and Chen, D. Sheared llama:
Accelerating language model pre-training via structured
pruning. In ICLR, 2024.
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., and Han,
S. Smoothquant: Accurate and efficient post-training
quantization for large language models. In International
Conference on Machine Learning, pp. 38087–38099.
PMLR, 2023.
Xu, X., Li, M., Tao, C., Shen, T., Cheng, R., Li, J., Xu,
C., Tao, D., and Zhou, T. A survey on knowledge
distillation of large language models. arXiv preprint
arXiv:2402.13116, 2024a.
Xu, Y., Han, X., Yang, Z., Wang, S., Zhu, Q., Liu, Z., Liu,
W., and Che, W. Onebit: Towards extremely low-bit
large language models. arXiv preprint arXiv:2402.11295,
b.
Yin, L., Wu, Y., Zhang, Z., Hsieh, C.-Y., Wang, Y., Jia, Y.,
Pechenizkiy, M., Liang, Y., Wang, Z., and Liu, S. Outlier
weighed layerwise sparsity (owl): A missing secret
sauce for pruning llms to high sparsity. arXiv preprint
arXiv:2310.05175, 2023.
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi,
Y. Hellaswag: Can a machine really finish your sentence?
arXiv preprint arXiv:1905.07830, 2019.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Shengkun Tang, Oliver Sieberling, Eldar Kurtic, Dan Alistarh

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.

