
Effective Mitigations for Systemic Risks from General-Purpose AI
DOI:
https://doi.org/10.70777/si.v2i1.13975Keywords:
agi risk mitigation, agi risks, artificial general intelligence risksAbstract
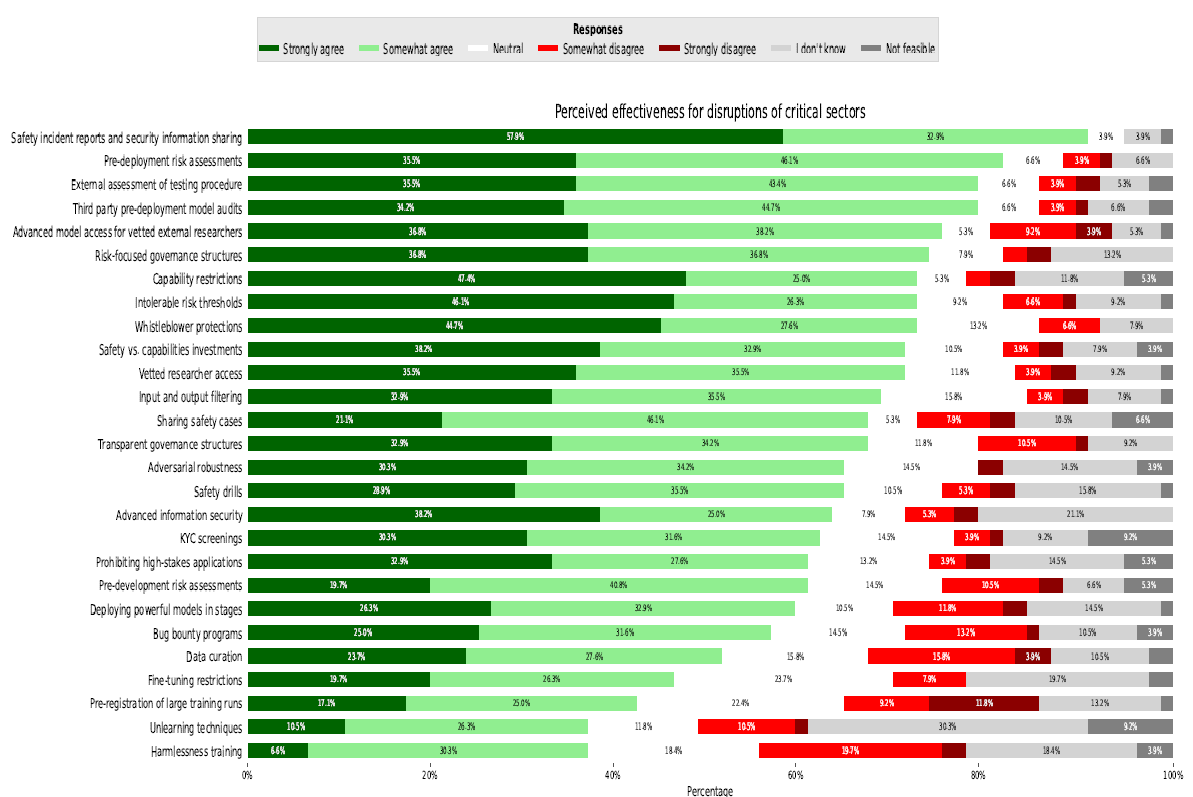
The systemic risks posed by general-purpose AI models are a growing concern, yet the effectiveness of mitigations remains underexplored. Previous research has proposed frameworks for risk mitigation, but has left gaps in our understanding of the perceived effectiveness of measures for mitigating systemic risks. Our study addresses this gap by evaluating how experts perceive different mitigations that aim to reduce the systemic risks of general-purpose AI models. We surveyed 76 experts whose expertise spans AI safety; critical infrastructure; democratic processes; chemical, biological, radiological, and nuclear risks (CBRN); and discrimination and bias. Among 27 mitigations identified through a literature review, we find that a broad range of risk mitigation measures are perceived as effective in reducing various systemic risks and technically feasible by domain experts. In particular, three mitigation measures stand out: safety incident reports and security information sharing, third-party pre-deployment model audits, and pre-deployment risk assessments. These measures show both the highest expert agreement ratings (>60%) across all four risk areas and are most frequently selected in experts’ preferred combinations of measures (>40%). The surveyed experts highlighted that external scrutiny, proactive evaluation and transparency are key principles for effective mitigation of systemic risks. We provide policy recommendations for implementing the most promising measures, incorporating the qualitative contributions from
The systemic risks posed by general-purpose AI models are a growing concern, yet the effectiveness of mitigations remains underexplored. Previous research has proposed frameworks for risk mitigation, but has left gaps in our understanding of the perceived effectiveness of measures for mitigating systemic risks. Our study addresses this gap by evaluating how experts perceive different mitigations that aim to reduce the systemic risks of general-purpose AI models. We surveyed 76 experts whose expertise spans AI safety; critical infrastructure; democratic processes; chemical, biological, radiological, and nuclear risks (CBRN); and discrimination and bias. Among 27 mitigations identified through a literature review, we find that a broad range of risk mitigation measures are perceived as effective in reducing various systemic risks and technically feasible by domain experts. In particular, three mitigation measures stand out: safety incident reports and security information sharing, third-party pre-deployment model audits, and pre-deployment risk assessments. These measures show both the highest expert agreement ratings (>60%) across all four risk areas and are most frequently selected in experts’ preferred combinations of measures (>40%). The surveyed experts highlighted that external scrutiny, proactive evaluation and transparency are key principles for effective mitigation of systemic risks. We provide policy recommendations for implementing the most promising measures, incorporating the qualitative contributions from
The systemic risks posed by general-purpose AI models are a growing concern, yet the effectiveness of mitigations remains underexplored. Previous research has proposed frameworks for risk mitigation, but has left gaps in our understanding of the perceived effectiveness of measures for mitigating systemic risks. Our study addresses this gap by evaluating how experts perceive different mitigations that aim to reduce the systemic risks of general-purpose AI models. We surveyed 76 experts whose expertise spans AI safety; critical infrastructure; democratic processes; chemical, biological, radiological, and nuclear risks (CBRN); and discrimination and bias. Among 27 mitigations identified through a literature review, we find that a broad range of risk mitigation measures are perceived as effective in reducing various systemic risks and technically feasible by domain experts. In particular, three mitigation measures stand out: safety incident reports and security information sharing, third-party pre-deployment model audits, and pre-deployment risk assessments. These measures show both the highest expert agreement ratings (>60%) across all four risk areas and are most frequently selected in experts’ preferred combinations of measures (>40%). The surveyed experts highlighted that external scrutiny, proactive evaluation and transparency are key principles for effective mitigation of systemic risks. We provide policy recommendations for implementing the most promising measures, incorporating the qualitative contributions from experts. These insights should inform regulatory frameworks and industry practices for mitigating the systemic risks associated with general-purpose AI.
References
Anthropic. (2024a). The Claude 3 Model Family: Opus, Sonnet,
Haiku. Retrieved from https://www-cdn.anthropic.com/
de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3
Barrett, A. M., Newman, J., Nonnecke, B., Hendrycks, D., Murphy, E. R.,
& Jackson, K. (2023). AI Risk-Management Standards Profile for
General-Purpose AI Systems (GPAIS) and Foundation Models. Retrieved
from https://cltc.berkeley.edu/publication/ai-risk-management
-standards-profile
Bengio, Y., Privitera, D., Besiroglu, T., Bommasani, R., Casper, S., Choi, Y.,
. . . Mindermann, S. (2024). International Scientific Report on the Safety
of Advanced AI: Interim Report. Retrieved from https://hal.science/
hal-04612963
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., . . .
Liang, P. (2022). On the Opportunities and Risks of Foundation Models.
arXiv. doi: 10.48550/arXiv.2108.07258
California State Portal. (2024). SB-1047 Safe and Secure Innovation
for Frontier Artificial Intelligence Models Act. Retrieved from
https://leginfo.legislature.ca.gov/faces/billNavClient.xhtml
?bill_id=202320240SB1047
Clarke, S., Whittlestone, J., Maas, M., Belfield, H., Hernández-Orallo,
J., & Ó hÉigeartaigh, S. (2021). Feedback from: University
of Cambridge. Retrieved from https://ec.europa.eu/info/law/
better-regulation/have-your-say/initiatives/12527-Artificial
-intelligence-ethical-and-legal-requirements/F2665626_en
EU AI High-Level Expert Group on Artificial Intelligence. (2019). Ethics
Guidelines for Trustworthy AI. Retrieved from https://www.aepd.es/
sites/default/files/2019-12/ai-ethics-guidelines.pdf
Future of Life Institute. (2021). FLI Position Paper on the EU AI Act.
Retrieved from https://futureoflife.org/document/fli-position
-paper-on-the-eu-ai-act/
Kolt, N. (2023). Algorithmic Black Swans. Washington University Law Review,
. Retrieved from https://papers.ssrn.com/sol3/papers.cfm
?abstract_id=4370566 (Forthcoming)
OpenAI. (2024b). OpenAI o1 System Card. Retrieved from https://cdn
.openai.com/o1-system-card-20240917.pdf
OpenAI. (2024c). Review Completed & Altman, Brockman to Continue to Lead
OpenAI. Retrieved from https://openai.com/index/review-completed
-altman-brockman-to-continue-to-lead-openai/
Partnership on AI. (2023). PAI’s Guidance for Safe Foundation
Model Deployment: A Framework for Collective Action.
Retrieved from https://partnershiponai.org/wp-content/uploads/
/10/PAI-Model-Deployment-Guidance.pdf
Schuett, J., et al. (2023). Towards Best Practices in AGI Safety and Governance.
SuperIntelligence – Robotics – Safety & Alignment 2025 2(1) Large Language Models I
Retrieved from https://cdn.governance.ai/AGI_Safety_Governance
_Practices_GovAIReport.pdf
Smuha, N. A. (2021). Beyond the Individual: Governing AI’s Societal Harm.
Internet Policy Review, 10 (3). doi: https://doi.org/10.14763/2021.3.1574 DOI: https://doi.org/10.14763/2021.3.1574
The White House. (2023). Ensuring Safe, Secure, and Trustworthy
AI. Retrieved from https://www.whitehouse.gov/wp-content/
uploads/2023/07/Ensuring-Safe-Secure-and-Trustworthy-AI.pdf
UK Government. (2023). Emerging Processes for Frontier AI Safety.
Retrieved from https://assets.publishing.service.gov.uk/
media/653aabbd80884d000df71bdc/emerging-processes-frontier
-ai-safety.pdf
UK Government. (2024). Frontier AI Safety Commitments, AI Seoul Summit
Retrieved from https://www.gov.uk/government/publications/
frontier-ai-safety-commitments-ai-seoul-summit-2024/
frontier-ai-safety-commitments-ai-seoul-summit-2024
Weidinger, L., et al. (2021). Ethical and Social Risks of Harm from Language
Models. arXiv. doi: 10.48550/arXiv.2112.04359
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Risto Uuk, Annemieke Brouwer, Tim Schreier, Noemi Dreksler, Valeria Pulignano, Rishi Bommasani

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.

