
Humanity's Last Exam
DOI:
https://doi.org/10.70777/si.v2i1.13973Keywords:
llm benchmarks, agi safety, llm capabilities, large language model capabilities, large language model benchmarks, agi benchmarks, artificial general intelligence benchmarksAbstract
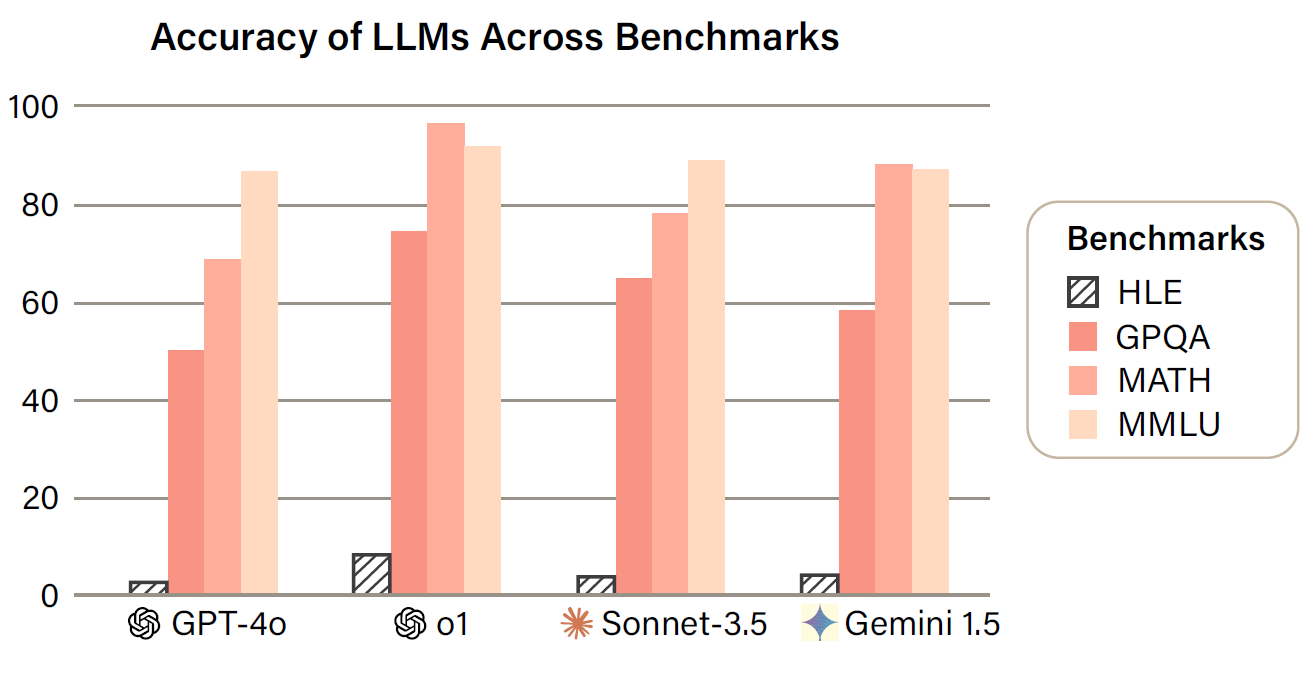
Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce HUMANITY’S LAST EXAM (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 2,700 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
References
C. Alberti, K. Lee, and M. Collins. A bert baseline for the natural questions, 2019. URL
https://arxiv.org/abs/1901.08634.
M. Andriushchenko, A. Souly, M. Dziemian, D. Duenas, M. Lin, J. Wang, D. Hendrycks,
A. Zou, Z. Kolter, M. Fredrikson, E. Winsor, J. Wynne, Y. Gal, and X. Davies. Agentharm: A
benchmark for measuring harmfulness of llm agents, 2024. URL https://arxiv.org/abs/
09024.
Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2024. URL https://api.
semanticscholar.org/CorpusID:268232499.
Anthropic. Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 sonnet,
URL https://assets.anthropic.com/m/1cd9d098ac3e6467/original/
Claude-3-Model-Card-October-Addendum.pdf.
Anthropic. Responsible scaling policy updates, 2024. URL https://www.anthropic.com/
rsp-updates.
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry,
Q. Le, and C. Sutton. Program synthesis with large language models, 2021. URL https:
//arxiv.org/abs/2108.07732.
Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli,
T. Henighan, N. Joseph, S. Kadavath, J. Kernion, T. Conerly, S. El-Showk, N. Elhage, Z. Hatfield-
Dodds, D. Hernandez, T. Hume, S. Johnston, S. Kravec, L. Lovitt, N. Nanda, C. Olsson,
D. Amodei, T. Brown, J. Clark, S. McCandlish, C. Olah, B. Mann, and J. Kaplan. Training a
helpful and harmless assistant with reinforcement learning from human feedback, 2022. URL
https://arxiv.org/abs/2204.05862.
P. Bajaj, D. Campos, N. Craswell, L. Deng, J. Gao, X. Liu, R. Majumder, A. McNamara,
B. Mitra, T. Nguyen, M. Rosenberg, X. Song, A. Stoica, S. Tiwary, and T. Wang. Ms marco: A
human generated machine reading comprehension dataset, 2018. URL https://arxiv.org/
abs/1611.09268.
M. Bhatt, S. Chennabasappa, C. Nikolaidis, S. Wan, I. Evtimov, D. Gabi, D. Song, F. Ahmad,
C. Aschermann, L. Fontana, S. Frolov, R. P. Giri, D. Kapil, Y. Kozyrakis, D. LeBlanc, J. Milazzo,
A. Straumann, G. Synnaeve, V. Vontimitta, S. Whitman, and J. Saxe. Purple llama cyberseceval:
A secure coding benchmark for language models, 2023. URL https://arxiv.org/abs/
04724.
J. S. Chan, N. Chowdhury, O. Jaffe, J. Aung, D. Sherburn, E. Mays, G. Starace, K. Liu,
L. Maksin, T. Patwardhan, L. Weng, and A. Ma˛dry. Mle-bench: Evaluating machine learning
agents on machine learning engineering, 2024. URL https://arxiv.org/abs/2410.07095.
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda,
N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry,
P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter,
P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H.
Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders,
C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight,
M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish,
I. Sutskever, and W. Zaremba. Evaluating large language models trained on code, 2021. URL
https://arxiv.org/abs/2107.03374.
F. Chollet, M. Knoop, G. Kamradt, and B. Landers. Arc prize 2024: Technical report, 2024.
URL https://arxiv.org/abs/2412.04604.
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek,
J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word
problems, 2021. URL https://arxiv.org/abs/2110.14168.
SuperIntelligence – Robotics – Safety & Alignment 2025 2(1) Large Language Models I
DeepSeek-AI. Deepseek-v3 technical report, 2024. URL https://github.com/
deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf.
D. Dua, Y. Wang, P. Dasigi, G. Stanovsky, S. Singh, and M. Gardner. Drop: A reading
comprehension benchmark requiring discrete reasoning over paragraphs, 2019. URL https:
//arxiv.org/abs/1903.00161.
A. Dubey et al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.
B. Gao, F. Song, Z. Yang, Z. Cai, Y. Miao, Q. Dong, L. Li, C. Ma, L. Chen, R. Xu, Z. Tang,
B. Wang, D. Zan, S. Quan, G. Zhang, L. Sha, Y. Zhang, X. Ren, T. Liu, and B. Chang. Omnimath:
A universal olympiad level mathematic benchmark for large language models, 2024.
URL https://arxiv.org/abs/2410.07985.
E. Glazer, E. Erdil, T. Besiroglu, D. Chicharro, E. Chen, A. Gunning, C. F. Olsson, J.-S.
Denain, A. Ho, E. de Oliveira Santos, O. Järviniemi, M. Barnett, R. Sandler, J. Sevilla, Q. Ren,
E. Pratt, L. Levine, G. Barkley, N. Stewart, B. Grechuk, T. Grechuk, and S. V. Enugandla.
Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai, 2024. URL
https://arxiv.org/abs/2411.04872.
C. He, R. Luo, Y. Bai, S. Hu, Z. L. Thai, J. Shen, J. Hu, X. Han, Y. Huang, Y. Zhang, J. Liu,
L. Qi, Z. Liu, and M. Sun. Olympiadbench: A challenging benchmark for promoting agi with
olympiad-level bilingual multimodal scientific problems, 2024. URL https://arxiv.org/
abs/2402.14008.
D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik,
H. He, D. Song, and J. Steinhardt. Measuring coding challenge competence with apps, 2021.
URL https://arxiv.org/abs/2105.09938.
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring
massive multitask language understanding, 2021. URL https://arxiv.org/abs/2009.
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt.
Measuring mathematical problem solving with the math dataset, 2021. URL https://arxiv.
org/abs/2103.03874.
D. Hendrycks, A. Zou, M. Mazeika, L. Tang, B. Li, D. Song, and J. Steinhardt. Pixmix:
Dreamlike pictures comprehensively improve safety measures, 2022. URL https://arxiv.
org/abs/2112.05135.
A. Hosseini, A. Sordoni, D. Toyama, A. Courville, and R. Agarwal. Not all llm reasoners are
created equal, 2024. URL https://arxiv.org/abs/2410.01748.
A. Jacovi, A. Wang, C. Alberti, C. Tao, J. Lipovetz, K. Olszewska, L. Haas, M. Liu, N. Keating,
A. Bloniarz, C. Saroufim, C. Fry, D. Marcus, D. Kukliansky, G. S. Tomar, J. Swirhun, J. Xing,
L. W. andMadhu Gurumurthy, M. Aaron, M. Ambar, R. Fellinger, R. Wang, R. Sims, Z. Zhang,
S. Goldshtein, and D. Das. Facts leaderboard. https://kaggle.com/facts-leaderboard,
Google DeepMind, Google Research, Google Cloud, Kaggle.
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench:
Can language models resolve real-world github issues?, 2024. URL https://arxiv.org/
abs/2310.06770.
D. Kiela, M. Bartolo, Y. Nie, D. Kaushik, A. Geiger, Z. Wu, B. Vidgen, G. Prasad, A. Singh,
P. Ringshia, Z. Ma, T. Thrush, S. Riedel, Z. Waseem, P. Stenetorp, R. Jia, M. Bansal, C. Potts,
and A. Williams. Dynabench: Rethinking benchmarking in nlp, 2021. URL https://arxiv.
org/abs/2104.14337.
P. Kumar, E. Lau, S. Vijayakumar, T. Trinh, S. R. Team, E. Chang, V. Robinson, S. Hendryx,
S. Zhou, M. Fredrikson, S. Yue, and Z. Wang. Refusal-trained llms are easily jailbroken as
browser agents, 2024. URL https://arxiv.org/abs/2410.13886.
SuperIntelligence – Robotics – Safety & Alignment 2025 2(1) Large Language Models I
J. M. Laurent, J. D. Janizek, M. Ruzo, M. M. Hinks, M. J. Hammerling, S. Narayanan, M. Ponnapati,
A. D. White, and S. G. Rodriques. Lab-bench: Measuring capabilities of language
models for biology research, 2024. URL https://arxiv.org/abs/2407.10362.
N. Li, A. Pan, A. Gopal, S. Yue, D. Berrios, A. Gatti, J. D. Li, A.-K. Dombrowski, S. Goel,
L. Phan, G. Mukobi, N. Helm-Burger, R. Lababidi, L. Justen, A. B. Liu, M. Chen, I. Barrass,
O. Zhang, X. Zhu, R. Tamirisa, B. Bharathi, A. Khoja, Z. Zhao, A. Herbert-Voss, C. B. Breuer,
S. Marks, O. Patel, A. Zou, M. Mazeika, Z. Wang, P. Oswal, W. Lin, A. A. Hunt, J. Tienken-
Harder, K. Y. Shih, K. Talley, J. Guan, R. Kaplan, I. Steneker, D. Campbell, B. Jokubaitis,
A. Levinson, J. Wang, W. Qian, K. K. Karmakar, S. Basart, S. Fitz, M. Levine, P. Kumaraguru,
U. Tupakula, V. Varadharajan, R. Wang, Y. Shoshitaishvili, J. Ba, K. M. Esvelt, A. Wang, and
D. Hendrycks. The wmdp benchmark: Measuring and reducing malicious use with unlearning,
URL https://arxiv.org/abs/2403.03218.
P. Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K.-W. Chang, M. Galley, and
J. Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts,
URL https://arxiv.org/abs/2310.02255.
T. R. McIntosh, T. Susnjak, N. Arachchilage, T. Liu, P. Watters, and M. N. Halgamuge.
Inadequacies of large language model benchmarks in the era of generative artificial intelligence,
URL https://arxiv.org/abs/2402.09880.
Y. Nie, A. Williams, E. Dinan, M. Bansal, J. Weston, and D. Kiela. Adversarial nli: A new
benchmark for natural language understanding, 2020. URL https://arxiv.org/abs/1910.
OpenAI. Openai o1 system card, 2024. URL https://cdn.openai.com/
o1-system-card-20240917.pdf.
OpenAI. Openai and los alamos national laboratory announce bioscience
research partnership, 2024. URL https://openai.com/index/
openai-and-los-alamos-national-laboratory-work-together/.
OpenAI. Introducing swe-bench verified, 2024. URL https://openai.com/index/
introducing-swe-bench-verified/.
OpenAI et al. Gpt-4 technical report, 2024. URL https://arxiv.org/abs/2303.08774.
S. Ott, A. Barbosa-Silva, K. Blagec, J. Brauner, and M. Samwald. Mapping global dynamics
of benchmark creation and saturation in artificial intelligence. Nature Communications, 13(1):
, 2022.
D. Owen. How predictable is language model benchmark performance?, 2024. URL https:
//arxiv.org/abs/2401.04757.
E. Perez, S. Ringer, K. Lukoši¯ut˙e, K. Nguyen, E. Chen, S. Heiner, C. Pettit, C. Olsson,
S. Kundu, S. Kadavath, A. Jones, A. Chen, B. Mann, B. Israel, B. Seethor, C. McKinnon,
C. Olah, D. Yan, D. Amodei, D. Amodei, D. Drain, D. Li, E. Tran-Johnson, G. Khundadze,
J. Kernion, J. Landis, J. Kerr, J. Mueller, J. Hyun, J. Landau, K. Ndousse, L. Goldberg, L. Lovitt,
M. Lucas, M. Sellitto, M. Zhang, N. Kingsland, N. Elhage, N. Joseph, N. Mercado, N. DasSarma,
O. Rausch, R. Larson, S. McCandlish, S. Johnston, S. Kravec, S. El Showk, T. Lanham,
T. Telleen-Lawton, T. Brown, T. Henighan, T. Hume, Y. Bai, Z. Hatfield-Dodds, J. Clark, S. R.
Bowman, A. Askell, R. Grosse, D. Hernandez, D. Ganguli, E. Hubinger, N. Schiefer, and
J. Kaplan. Discovering language model behaviors with model-written evaluations, 2022. URL
https://arxiv.org/abs/2212.09251.
M. Phuong, M. Aitchison, E. Catt, S. Cogan, A. Kaskasoli, V. Krakovna, D. Lindner, M. Rahtz,
Y. Assael, S. Hodkinson, H. Howard, T. Lieberum, R. Kumar, M. A. Raad, A. Webson, L. Ho,
S. Lin, S. Farquhar, M. Hutter, G. Deletang, A. Ruoss, S. El-Sayed, S. Brown, A. Dragan,
R. Shah, A. Dafoe, and T. Shevlane. Evaluating frontier models for dangerous capabilities,
URL https://arxiv.org/abs/2403.13793.
SuperIntelligence – Robotics – Safety & Alignment 2025 2(1) Large Language Models I
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang. Squad: 100,000+ questions for machine
comprehension of text, 2016. URL https://arxiv.org/abs/1606.05250.
P. Rajpurkar, R. Jia, and P. Liang. Know what you don’t know: Unanswerable questions for
squad, 2018. URL https://arxiv.org/abs/1806.03822.
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R.
Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URL https://arxiv.
org/abs/2311.12022.
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani,
H. Cole-Lewis, S. Pfohl, et al. Large language models encode clinical knowledge. Nature, 620
(7972):172–180, 2023. DOI: https://doi.org/10.1176/appi.ajp.23180002
V. K. Srinivasan, Z. Dong, B. Zhu, B. Yu, H. Mao, D. Mosk-Aoyama, K. Keutzer, J. Jiao,
and J. Zhang. Nexusraven: A commercially-permissive language model for function calling.
In NeurIPS 2023 Foundation Models for Decision Making Workshop, 2023. URL https:
//openreview.net/forum?id=5lcPe6DqfI.
A. Srivastava, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. R. Brown, A. Santoro,
A. Gupta, A. Garriga-Alonso, A. Kluska, A. Lewkowycz, A. Agarwal, A. Power, A. Ray,
A. Warstadt, A. W. Kocurek, A. Safaya, A. Tazarv, A. Xiang, A. Parrish, A. Nie, A. Hussain,
A. Askell, A. Dsouza, A. Slone, A. Rahane, A. S. Iyer, A. Andreassen, A. Madotto, A. Santilli,
A. Stuhlmüller, A. Dai, A. La, A. Lampinen, A. Zou, et al. Beyond the imitation game:
Quantifying and extrapolating the capabilities of language models, 2023. URL https://
arxiv.org/abs/2206.04615.
S. A. Taghanaki, A. Khani, and A. Khasahmadi. Mmlu-pro+: Evaluating higher-order reasoning
and shortcut learning in llms, 2024. URL https://arxiv.org/abs/2409.02257.
G. Team et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of
context, 2024. URL https://arxiv.org/abs/2403.05530.
G. Tsoukalas, J. Lee, J. Jennings, J. Xin, M. Ding, M. Jennings, A. Thakur, and S. Chaudhuri.
Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition,
URL https://arxiv.org/abs/2407.11214.
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Glue: A multi-task
benchmark and analysis platform for natural language understanding, 2019. URL https:
//arxiv.org/abs/1804.07461.
A.Wang, Y. Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman.
Superglue: A stickier benchmark for general-purpose language understanding systems, 2020.
URL https://arxiv.org/abs/1905.00537.
Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang,
T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. Mmlu-pro: A more robust
and challenging multi-task language understanding benchmark (published at neurips 2024 track
datasets and benchmarks), 2024. URL https://arxiv.org/abs/2406.01574.
J. Wei, N. Karina, H. W. Chung, Y. J. Jiao, S. Papay, A. Glaese, J. Schulman, and W. Fedus.
Measuring short-form factuality in large language models, 2024. URL https://arxiv.org/
abs/2411.04368.
H. Wijk, T. Lin, J. Becker, S. Jawhar, N. Parikh, T. Broadley, L. Chan, M. Chen, J. Clymer,
J. Dhyani, E. Ericheva, K. Garcia, B. Goodrich, N. Jurkovic, M. Kinniment, A. Lajko, S. Nix,
L. Sato, W. Saunders, M. Taran, B. West, and E. Barnes. Re-bench: Evaluating frontier
ai r&d capabilities of language model agents against human experts, 2024. URL https:
//arxiv.org/abs/2411.15114.
xAI. Grok-2 beta release, 2024. URL https://x.ai/blog/grok-2.
SuperIntelligence – Robotics – Safety & Alignment 2025 2(1) Large Language Models I
F. Yan, H. Mao, C. C.-J. Ji, T. Zhang, S. G. Patil, I. Stoica, and J. E. Gonzalez. Berkeley
function calling leaderboard. https://gorilla.cs.berkeley.edu/blogs/8_berkeley_
function_calling_leaderboard.html, 2024.
Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning.
Hotpotqa: A dataset for diverse, explainable multi-hop question answering, 2018. URL
https://arxiv.org/abs/1809.09600.
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan. τ -bench: A benchmark for tool-agent-user
interaction in real-world domains, 2024. URL https://arxiv.org/abs/2406.12045.
A. K. Zhang, N. Perry, R. Dulepet, J. Ji, J. W. Lin, E. Jones, C. Menders, G. Hussein, S. Liu,
D. Jasper, P. Peetathawatchai, A. Glenn, V. Sivashankar, D. Zamoshchin, L. Glikbarg, D. Askaryar,
M. Yang, T. Zhang, R. Alluri, N. Tran, R. Sangpisit, P. Yiorkadjis, K. Osele, G. Raghupathi,
D. Boneh, D. E. Ho, and P. Liang. Cybench: A framework for evaluating cybersecurity capabilities
and risks of language models, 2024. URL https://arxiv.org/abs/2408.08926.
W. Zhong, R. Cui, Y. Guo, Y. Liang, S. Lu, Y. Wang, A. Saied, W. Chen, and N. Duan.
Agieval: A human-centric benchmark for evaluating foundation models, 2023. URL https:
//arxiv.org/abs/2304.06364.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.

